
服务热线
135-6963-3175
Sentinel源码分析-Node分析
Sentinel中有很多类型的Node,例如DefaultNode、StatisticNode、ClusterNode、还有个EntranceNode总共四种类型的Node。
DefaultNode:保存着某个resource在某个context中的实时指标,每个DefaultNode都指向一个ClusterNode
ClusterNode:保存着某个resource在所有的context中实时指标的总和,同样的resource会共享同一个ClusterNode,不管他在哪个context中。
我们看到StatisticSlot中使用了Node去统计了请求信息,那么Node应该就是做请求统计用的,看下Node接口里定义
public interface Node {
long totalRequest();
long totalSuccess();
long blockRequest();
long totalException();
long passQps();
long blockQps();
long totalQps();
long successQps();
long maxSuccessQps();
long exceptionQps();
long avgRt();
long minRt();
int curThreadNum();
long previousBlockQps();
long previousPassQps();
Map<Long, MetricNode> metrics();
void addPassRequest(int count);
void addRtAndSuccess(long rt, int success);
void increaseBlockQps(int count);
void increaseExceptionQps(int count);
void increaseThreadNum();
void decreaseThreadNum();
void reset();
void debug();
}内部实现可以不说,但是对外部来说Node是做为一个请求数据统计和获取的载体
另外再看下四个Node的关系:
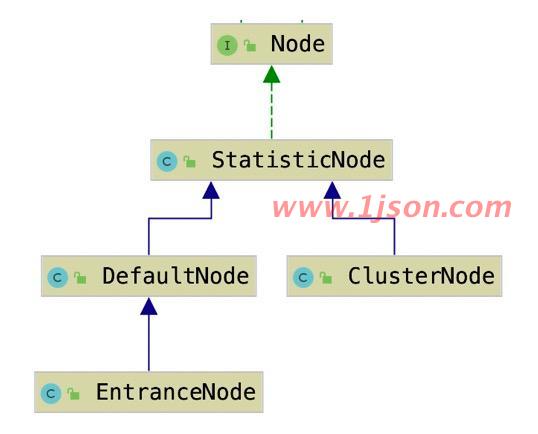
那么这四个Node中,哪个去实现了Node接口的方法呢? 通过代码看到是StatisticNode实现了Node接口的所有方法,也就是说,另外三个Node有两种可能的作用:
DefaultNode、ClusterNode、EntranceNode继承于StatisticNode,基于其提供的数据统计和获取方法,实现自身一些特殊逻辑
StatisticNode提供了默认的方法,DefaultNode、ClusterNode、DntranceNode有自身的计算逻辑,需要重写这些方法
示例代码:
ContextUtil.enter("entrance1", "appA");
Entry nodeA = SphU.entry("nodeA");
if (nodeA != null) {
nodeA.exit();
}
ContextUtil.exit();ContextUtil的初始化工作
1、创建一个入口节点node EntranceNode,id为上下文名称sentinel_default_context(默认值)
2、初始化root节点
3、并将步骤1的节点增加为root的子节点。
4、并将步骤1创建的节点放入key-node集合。Map<String, DefaultNode>,key为上下文名称sentinel_default_context
root节点:(是一个DefaultNode也是一个EntranceNode) 关联了一个ClusterNode,root节点(id为machine-root)可以挂子节点,子节点为上下文节点。
machine-root / \ / \ EntranceNode (sentinel_default_content)
EntranceNode
我们从入口开始分析了整个调用链路流程,最先遇到和Node相关的代码的时候,是在ContextUtil#enter-#trueEnter中
//#com.alibaba.csp.sentinel.Constants
public final static DefaultNode ROOT = new EntranceNode(new StringResourceWrapper(ROOT_ID, EntryType.IN),
Env.nodeBuilder.buildClusterNode());
//ContextUtil#trueEnter
protected static Context trueEnter(String name, String origin) {
Context context = contextHolder.get();
if (context == null) {
Map<String, DefaultNode> localCacheNameMap = contextNameNodeMap;
DefaultNode node = localCacheNameMap.get(name);
if (node == null) {
if (contextNameNodeMap.size() > Constants.MAX_CONTEXT_NAME_SIZE) {
//....
} else {
node = new EntranceNode(new StringResourceWrapper(name, EntryType.IN), null);
// Add entrance node.
Constants.ROOT.addChild(node);
Map<String, DefaultNode> newMap = new HashMap<String, DefaultNode>(
contextNameNodeMap.size() + 1);
newMap.putAll(contextNameNodeMap);
newMap.put(name, node);
contextNameNodeMap = newMap;
}
}
//....
context = new Context(node, name);
context.setOrigin(origin);
contextHolder.set(context);
}
return context;
}(1)trueEnter方法的执行类似初始化工作中的1、3、4步骤,创建的节点也是EntranceNode,指定id值为传入的name。
(2)根据步骤(1)创建的node和name创建上下文对象Context,并设置调用来源为origin,然后把context绑定到当前线程。
machine-root / \ / \ EntranceNode EntranceNode (sentinel_dxx_content) (name)
这里可以看到,一个ContextName会对应一个EntranceNode,EntranceNode从字面意思来看,叫做入口节点,也就是说,一个上下文开始的时候,会创建一个EntranceNode与其对应,代表该上下文的入口。
另外看到EntranceNode会挂在ROOT节点下面,而ROOT又是一个EntranceNode节点,而其是全局唯一的,他代表应用的入口节点,如下
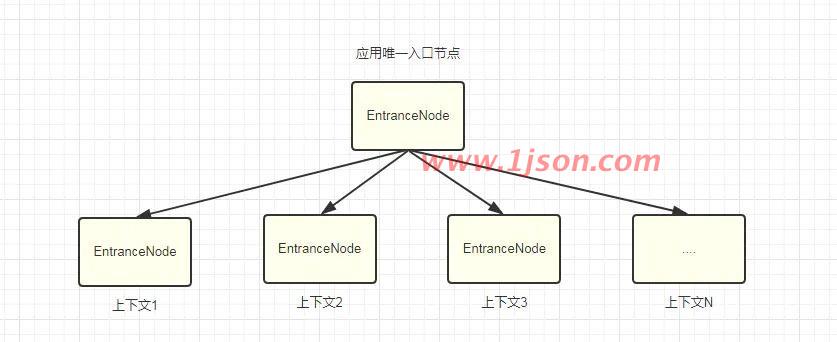
ROOT是一个EntranceNode类型的节点,他可以挂子节点,子节点为上下文节点,那么上下文节点下面挂的是啥?别急,我们继续分析
接下看下类的定义
public class EntranceNode extends DefaultNode {
public EntranceNode(ResourceWrapper id, ClusterNode clusterNode) {
super(id, clusterNode);
}
@Override
public long avgRt() {
long total = 0;
long totalQps = 0;
for (Node node : getChildList()) {
total += node.avgRt() * node.passQps();
totalQps += node.passQps();
}
return total / (totalQps == 0 ? 1 : totalQps);
}
@Override
public long blockQps() {
long blockQps = 0;
for (Node node : getChildList()) {
blockQps += node.blockQps();
}
return blockQps;
}
@Override
public long blockRequest() {
long r = 0;
for (Node node : getChildList()) {
r += node.blockRequest();
}
return r;
}
@Override
public int curThreadNum() {
int r = 0;
for (Node node : getChildList()) {
r += node.curThreadNum();
}
return r;
}
@Override
public long totalQps() {
long r = 0;
for (Node node : getChildList()) {
r += node.totalQps();
}
return r;
}
@Override
public long successQps() {
long r = 0;
for (Node node : getChildList()) {
r += node.successQps();
}
return r;
}
@Override
public long passQps() {
long r = 0;
for (Node node : getChildList()) {
r += node.passQps();
}
return r;
}
@Override
public long totalRequest() {
long r = 0;
for (Node node : getChildList()) {
r += node.totalRequest();
}
return r;
}
}可以看到EntranceNode重写了获取数据统计的方法,获取的时候将所有子节点的数据全累加后返回
SphU.entry(name)
1、创建entry对象CtEntry
2、然后给context设置curEntry,(同时若context-curEntry不为空则把当前创建的ctEntry设置为context-curEntry的child)
3、执行solt链
DefaultNode
第二次遇到与Node相关的应该是调用链中的NodeSelectorSlot,在看代码之前,先看下类上的注释,其中注释里画两个图:
machine-root / \ / \ EntranceNode1 EntranceNode2 / \ / \ DefaultNode(nodeA) DefaultNode(nodeA) | | +- - - - - - - - - - +- - - - - - -> ClusterNode(nodeA);
EntranceNode1和EntranceNode2表示两个不同的上下文,而上下文节点下分别挂了个DefaultNode
//com.alibaba.csp.sentinel.slots.nodeselector.NodeSelectorSlot#entry
public void entry(Context context, ResourceWrapper resourceWrapper, Object obj, int count, boolean prioritized, Object... args)
throws Throwable {
DefaultNode node = map.get(context.getName());
if (node == null) {
synchronized (this) {
node = map.get(context.getName());
if (node == null) {
node = Env.nodeBuilder.buildTreeNode(resourceWrapper, null);
HashMap<String, DefaultNode> cacheMap = new HashMap<String, DefaultNode>(map.size());
cacheMap.putAll(map);
cacheMap.put(context.getName(), node);
map = cacheMap;
}
((DefaultNode)context.getLastNode()).addChild(node);
}
}
context.setCurNode(node);
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}
// com.alibaba.csp.sentinel.node.DefaultNodeBuilder#buildTreeNode
public DefaultNode buildTreeNode(ResourceWrapper id, ClusterNode clusterNode) {
return new DefaultNode(id, clusterNode);
}这里与EntranceNode的创建有点类似,都是以ContextName为key去保存的,也就是说DefaultNode也是和上下文相关的节点。
步骤说明:
1、从全局map中取,如果资源节点不存在,则创建DefaultNode节点,并且放入缓存cacheMap(key为上下文名称,v为node)并把该节点给当前context的入口节点或者curEntry节点做绑定
2、设置context-curNode为步骤1创建或获取的节点
当创建成功后,会调用DefaultNode的addChild方法将创建的DefaultNode挂在某个节点下,我们看下getLastNode返回的是什么
/**
* Current processing entry.
*/
private Entry curEntry;
public Node getLastNode() {
if (curEntry != null && curEntry.getLastNode() != null) {
return curEntry.getLastNode();
} else {
return entranceNode;
}
}curEntry是什么?SphU创建entry相关entryWithPriority方法中,有如下代码
Entry e = new CtEntry(resourceWrapper, chain, context);// 1
try {
chain.entry(context, resourceWrapper, null, count, prioritized, args);
} catch (BlockException e1) {
e.exit(count, args);
throw e1;
} catch (Throwable e1) {
// This should not happen, unless there are errors existing in Sentinel internal.
RecordLog.info("Sentinel unexpected exception", e1);
}注意看标记1这个位置,这里创建了一个Entry,并将创建好的上下文对象作为参数传进去,看下其构造方法
CtEntry(ResourceWrapper resourceWrapper, ProcessorSlot<Object> chain, Context context) {
super(resourceWrapper);
this.chain = chain;
this.context = context;
setUpEntryFor(context);
}
private void setUpEntryFor(Context context) {
if (context instanceof NullContext) {
return;
}
this.parent = context.getCurEntry();//1
if (parent != null) {//2
((CtEntry)parent).child = this;//3
}
context.setCurEntry(this);//4
}1~3:获取当前上下文的curEntry,如果不为空,则表示当前上下文中,在创建Entry之前就已经有一个Entry被创建过了,那么需要设置父子关系
4:这个地方就是我们要找的curEntry初始化的地方
setUpEntryFor方法可能有点难理解,什么情况下parent不为空,首先要知道的是只有我们调用SphU#entry方法的时候才会创建一个Entry,即Entry代表一个当前调用的一个标志,假设我们在一次上下文中调用了多次,也是可行的,那么这时候会创建多个Entry,如以下代码:
ContextUtil.enter("contextName1");
Entry entry1 = null;
try {
entry1 = SphU.entry("resourceName1");
System.out.println("run method 1");
Entry entry2 = null;
try {
entry2 = SphU.entry("resourceName2");
System.out.println("run method 1");
}finally {
if (entry2 != null) {
entry2.exit();
}
}
} finally {
if (entry1 != null) {
entry1.exit();
}
}这种情况下,entry2的parent就是entry1,而entry1的parent为空
分析完curEntry的获取后 ,再回到getLastNode方法,当curEntry不为空,还需要再判断一下curEntry.getLastNode是否为空,看下其实现
//com.alibaba.csp.sentinel.CtEntry#getLastNode
public Node getLastNode() {
return parent == null ? null : parent.getCurNode();
}如果当前Entry有parent,则返回其parent对应的节点,如果parent为空,则返回Context对应的EntranceNode
那么在上面的栗子中,entry1进入到NodeSelectorSlot#entry方法的时候,由于parent为空,所以curEntry != null && curEntry.getLastNode() != null这行代码为false,Context#getLastNode方法返回EntranceNode,这样说可能不好理解,现在以上面的代码为例,一步步分析Entry和Node所构成的结构
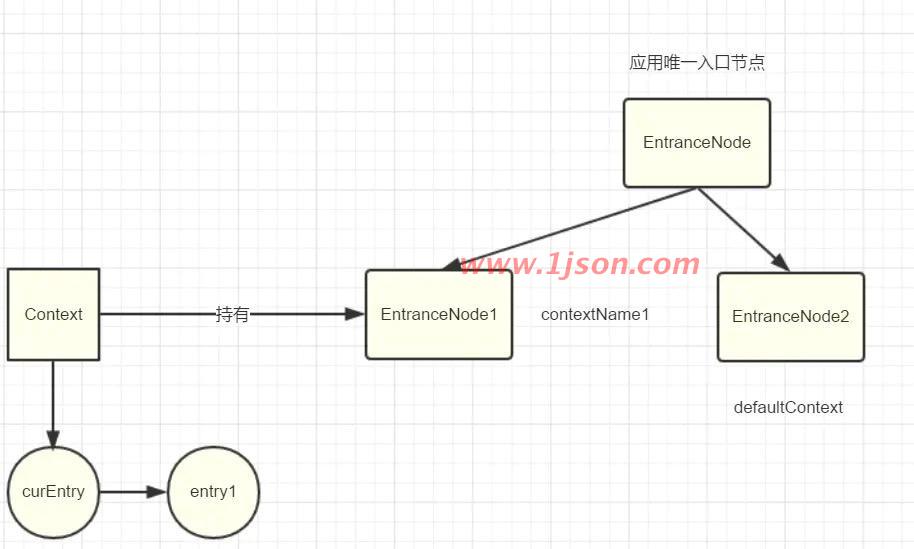
EntranceNode1在ContextUtil#trueEnter中被创建且和上下文Context绑定
curEntry在entryWithPriority方法中初始化且和上下文Context绑定,curEntry也即使代码中的entry1。
这时候代码执行到((DefaultNode)context.getLastNode()).addChild,由于curEntry即entry1没有parent,所以context.getLastNode()返回的是EntranceNode1,将创建的DefaultNode挂在其下面,此时结构如下:
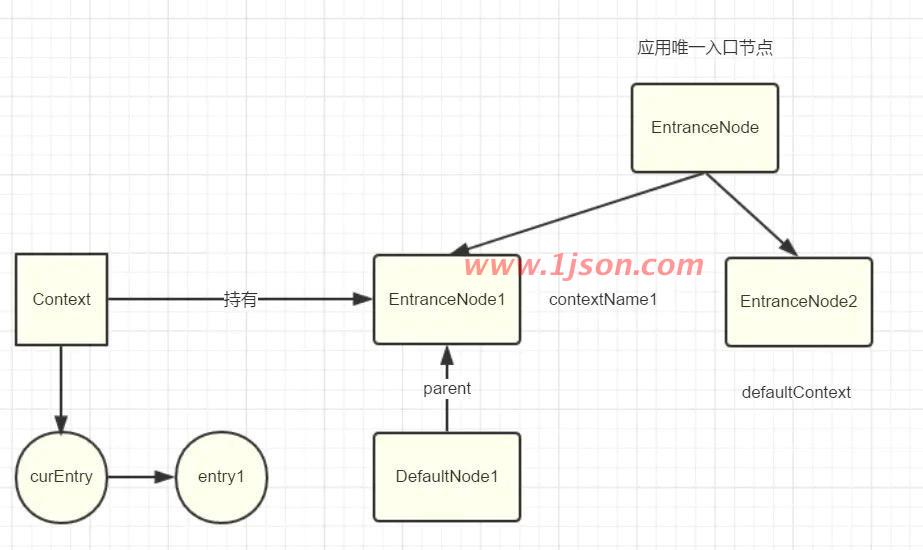
代码继续走到context.setCurNode(node);即curEntry.setCurNode(node),执行完毕后,此时结构
如下:
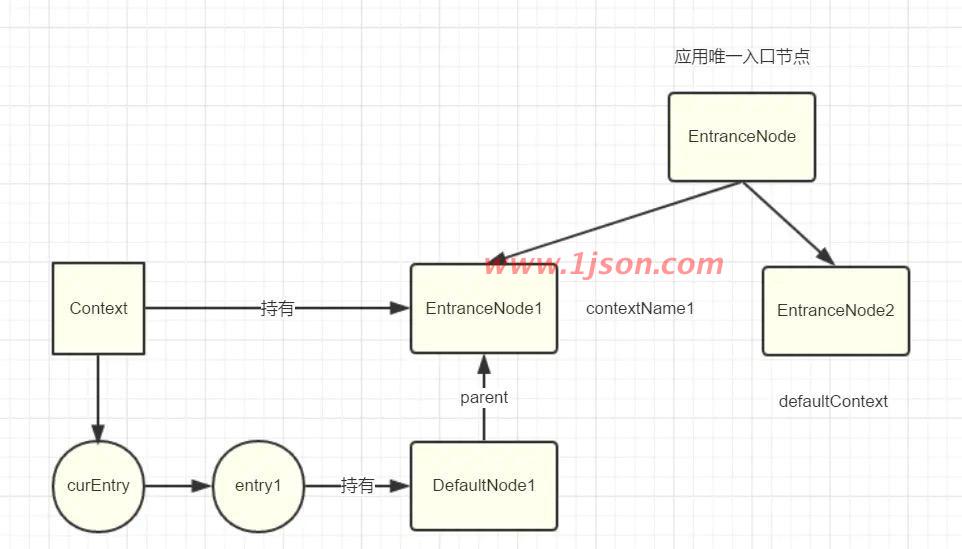
然后entry1继续往后执行,执行完毕后,entry2有执行NodeSelectorSlot#entry方法,此时结构如下:
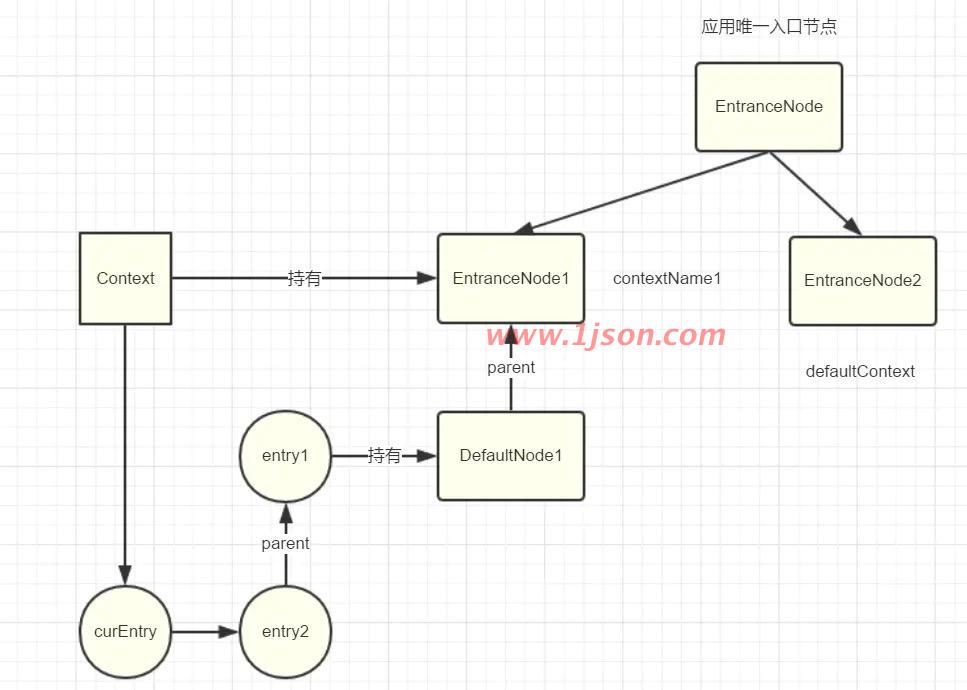
curEntry的变化在entryWithPriority方法中处理
代码继续走到((DefaultNode)context.getLastNode()).addChild,这时候由于curEntry的parent不为空,那么就会去到DefaultNode1,将创建的DefaultNode挂在其下面,执行完毕后,此时结构如下:
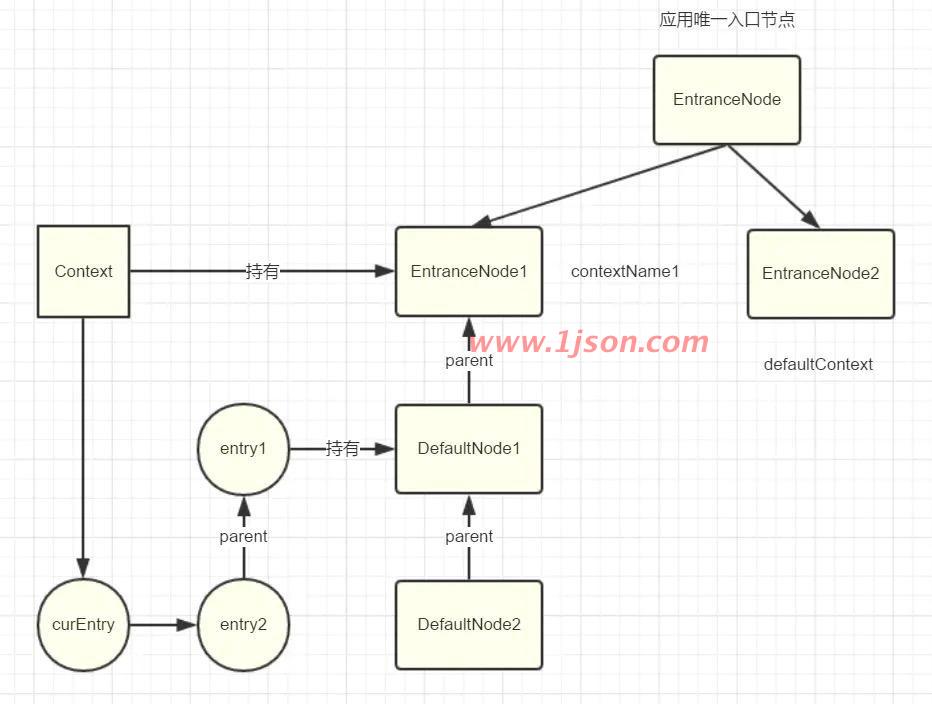
代码继续走到context.setCurNode(node),执行完毕后,此时结构如下:
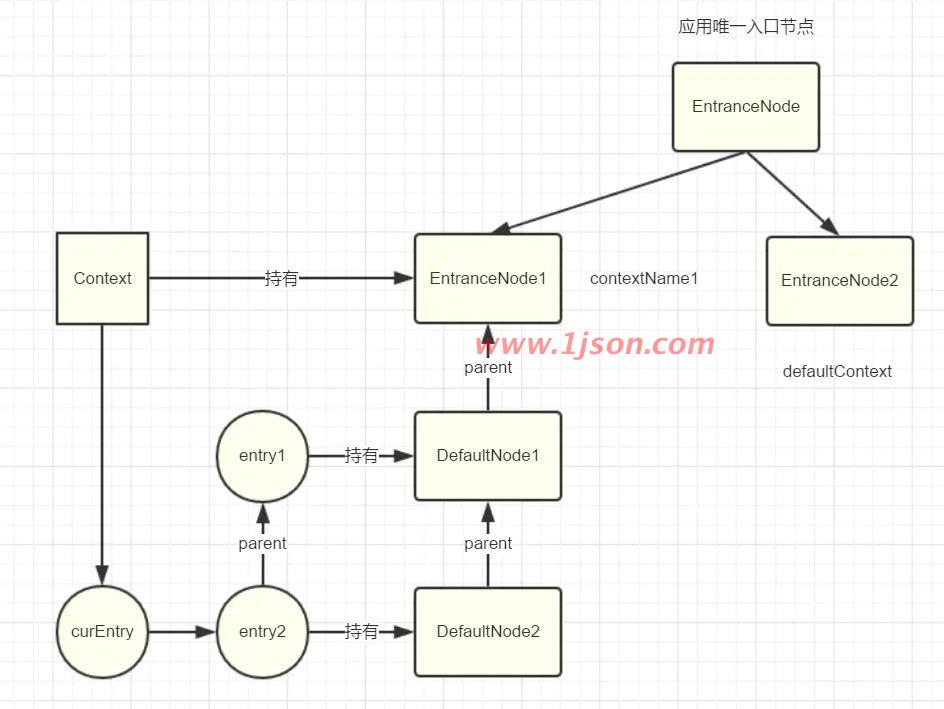
好了,到此为止,了解整个节点链路的构建过程,可以发现,对于一个资源,在同个上下文中,多次调用entry,会创建多个DefaultNode节点,这些节点依次挂在上下文的入口节点EntranceNode下面,而每个节点会负责当前上下文中调用entry后一个代码块的的请求数据的统计,记住,DefaultNode是与上下文相关的,假设是不同上下文,那么会呈现之前发过的结构
* machine-root * / \ * / \ * EntranceNode1 EntranceNode2 * / \ * / \ * DefaultNode(nodeA) DefaultNode(nodeA) * | | * +- - - - - - - - - - +- - - - - - -> ClusterNode(nodeA)
最下面两个DefaultNode是在不同上下文中调用entry所产生的结构(每个上下文只调用一次entry)
ClusterNode
终于轮到最后一个Node了,在NodeSelectorSlot之后,还有个ClusterBuilderSlot,其中有ClusterNode的处理
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args)
throws Throwable {
if (clusterNode == null) {
synchronized (lock) {
if (clusterNode == null) {
// Create the cluster node.
clusterNode = Env.nodeBuilder.buildClusterNode();
HashMap<ResourceWrapper, ClusterNode> newMap = new HashMap<ResourceWrapper, ClusterNode>(Math.max(clusterNodeMap.size(), 16));
newMap.putAll(clusterNodeMap);
newMap.put(node.getId(), clusterNode);
clusterNodeMap = newMap;
}
}
}
node.setClusterNode(clusterNode);
if (!"".equals(context.getOrigin())) {
Node originNode = node.getClusterNode().getOrCreateOriginNode(context.getOrigin());
context.getCurEntry().setOriginNode(originNode);
}
fireEntry(context, resourceWrapper, node, count, prioritized, args);
}可以看到这里也有个Map结构,但是,key是资源,而不是像以前那样是上下文,所以这里就已经清楚了,ClusterNode和资源绑定,即使是不同上下文,同一个资源,应该都是只有一个ClusterNode,由其进行流量统计
另外,当创建完成后还会调用node.setClusterNode(clusterNode);将ClusterNode与DefaultNode进行关联,即不同的DefaultNode都关联了一个ClusterNode,这样我们在不同上下文中都可以拿到当前资源一个总的流量统计情况
接着再看下DefaultNode重写的方法,以其中两个为例
@Override
public void increaseBlockQps(int count) {
super.increaseBlockQps(count);
this.clusterNode.increaseBlockQps(count);
}
@Override
public void increaseExceptionQps(int count) {
super.increaseExceptionQps(count);
this.clusterNode.increaseExceptionQps(count);
}统计方法中,除了调用父类(即StatisticNode)来统计本身的一个流量外,还会再调用ClusterNode的相应方法统计整个资源的一个流量
OriginNode
OriginNode整个东西其实在代码中没有对应的类,只不过是概念上的,其本身还是StatisticNode,这个东西又是什么呢,在ClusterBuilderSlot中有以下代码:
if (!"".equals(context.getOrigin())) {
Node originNode = node.getClusterNode().getOrCreateOriginNode(context.getOrigin());
context.getCurEntry().setOriginNode(originNode);
}假设origin属性不为空,从通过origin去获取一个Node节点,然后放到Context中,getOrCreateOriginNode方法内部逻辑比较简单,就是通过origin去获取一个StatisticNode,他是与origin属性绑定的,那么origin是什么呢?
在使用ContextUtil创建上下文的时候,其实是可以传入origin参数的,这个就是上面的origin,他代表的是请求来源,例如我有三个dubbo服务,分别是A和B、C,调用关系为A->C,B->C那么C在限流的时候,可以将A和B作为origin传入,那么ClusterBuilderSlot就会为其创建对应节点,用来统计AB服务对B服务调用的一个总体情况
总结
1.StatisticNode实现了Node接口,封装了基础的流量统计和获取方法
2.EntranceNode代表入口节点,每个上下文都会有一个入口节点,用来统计当前上下文的总体流量情况
3.DefaultNode代表同个资源在不同上下文中各自的流量情况
4.ClusterNode代表同个资源在不同上下文中总体的流量情况
5.OriginNode是一个StatisticNode类型的节点,代表了同个资源请求来源的流量情况
