
服务热线
135-6963-3175
通过探针自动收集所需的指标,并进行分布式追踪。通过这些调用链路以及指标,Skywalking APM会感知应用间关系和服务间关系,并进行相应的指标统计。如下架构图
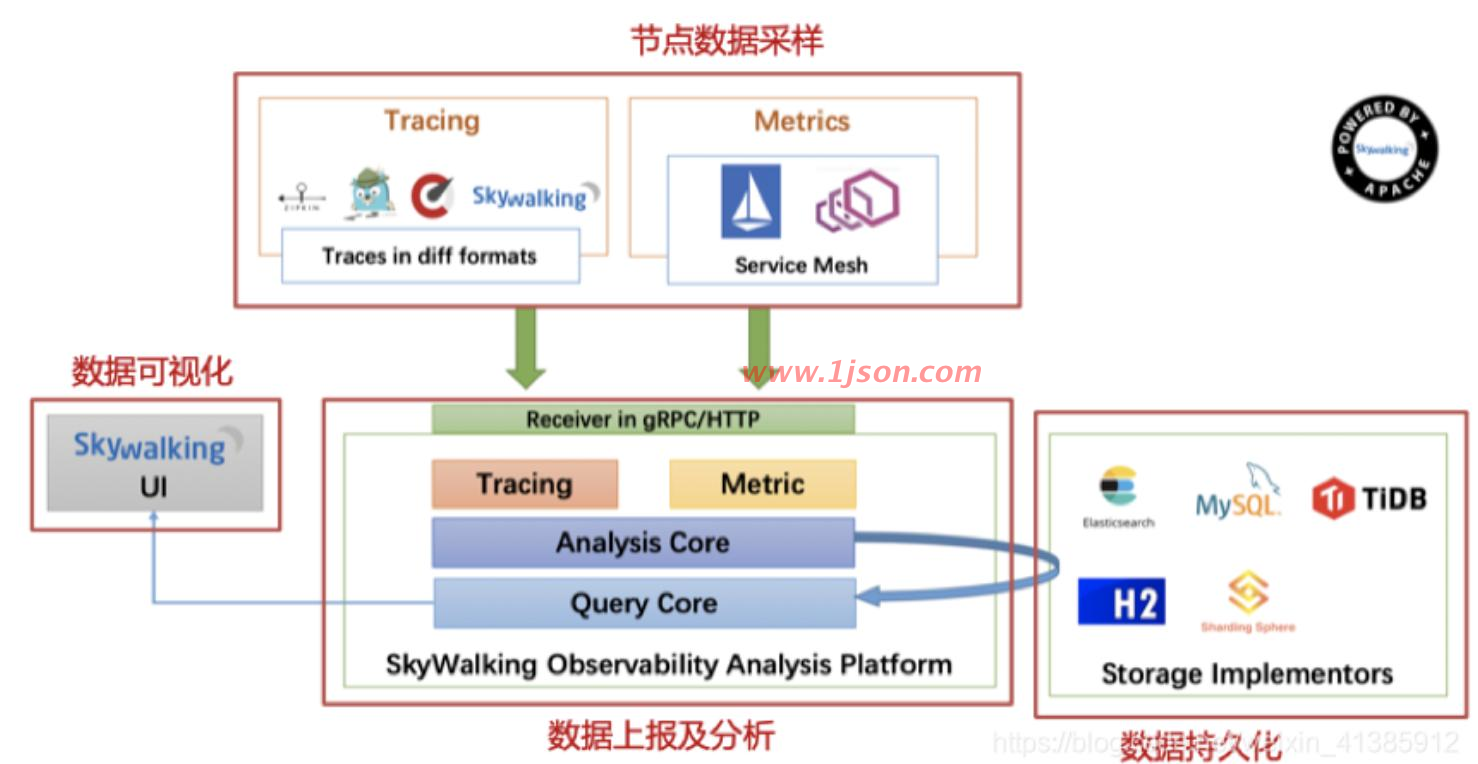
skywalking总体架构分为三部分
skywalking-collector
链路数据归集器,storage存储可用mysql、es等。
接收探针发送的数据,并在内存中使用分析引擎(Analysis Core)进行数据的整合运算,然后将数据存储到对应的存储介质上,比如 Elasticsearch、MySQL数据库、H2数据库等。同时OAP还使用查询引擎(Query Core)提供HTTP查 询接口。
skywalking-web
web可视化平台,提供单独的UI进行数据的查看,此时UI会调用OAP提供的接口,获取对应的数据然后进行展示。
skywalking-agent
探针,用来收集和发送数据到归集器,探针(agent)负责进行数据的收集,包含了Tracing和Metrics的数据。
三种场景
1、metrics指标性统计
全局、服务、实例和接口端点维度的吞吐量及平均吞吐量、服务访问指标、成功率、慢端点(接口),jvm,gc等等
并提供了告警机制,可根据不同的指标配置不同的规则实现告警。也可通过集成prometheus遥测方式收集sk metrics实现指标告警监控。
2、Tracing分布式追踪
可以看到接收到一次请求穿透整个系统的每个过程。包括底层http、rest、feign调用等和相应的响应时间,跨度。
每个跨度都可看到明细信息。如数据db上可看到具体执行的sql。
3、Logging日志记录
可集成logback等相关组件,实现打印日志自动跟上traceId等,并实现日志以grpc方式自动上传收集到oap
什么是OpenTracing
是一个规范,不是数据结构,介于日志分析程序和我们的应用程序之间。是要实现的一套api的套件,按照openTracing的规范向用户提供api,实现把数据下送到api的探针或tracer的探针。主旨是在做手动埋点,程序的开发者主动调用tracing的api。
规范数据模型主要有三个:
Trace:一个完整请求链路
Span:一次调用过程(需要有开始时间和结束时间)
SpanContext:Trace 的全局上下文信息, 如里面有traceId
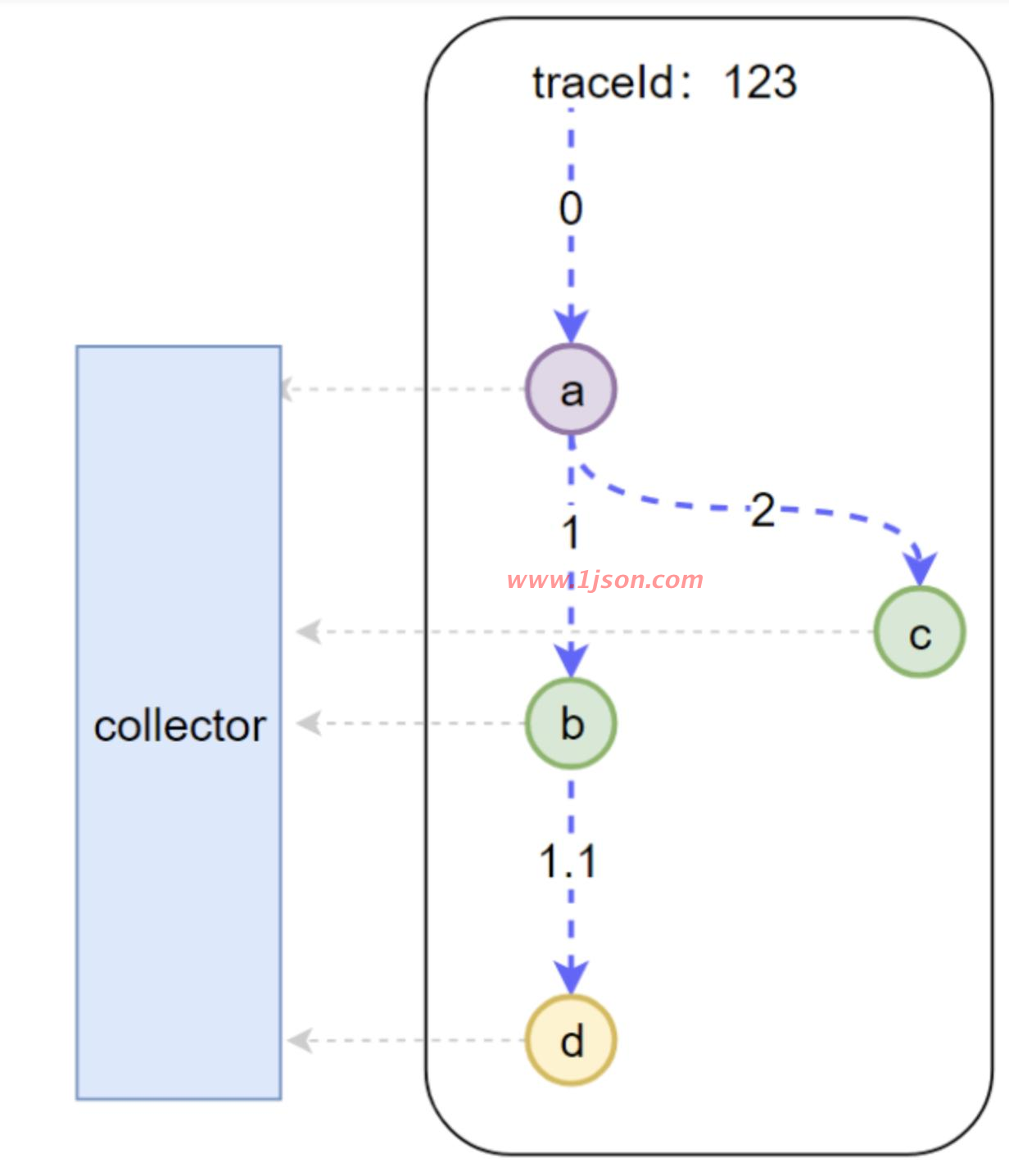
一次下单的完整请求完整就是一个 Trace, 显然对于这个请求来说,必须要有一个全局标识来标识这一个请求,每一次调用就称为一个 Span,每一次调用都要带上全局的 TraceId, 这样才可把全局 TraceId 与每个调用关联起来,这个 TraceId 就是通过 SpanContext 传输的,既然要传输显然都要遵循协议来调用。我们把传输协议比作车,把 SpanContext 比作货,把 Span 比作路应该会更好理解一些。
我们可以看到底层有一个 Collector 一直在默默无闻地收集数据,那么每一次调用 Collector 会收集哪些信息呢。
全局 trace_id:这是显然的,这样才能把每一个子调用与最初的请求关联起来
span_id: 图中的 0,1,1.1,2,这样就能标识是哪一个调用
parent_span_id:比如 b 调用 d 的 span_id 是 1.1,那么它的 parent_span_id 即为 a 调用 b 的 span_id 即 1,这样才能把两个紧邻的调用关联起来。
有了这些信息,Collector 收集的每次调用的信息如下
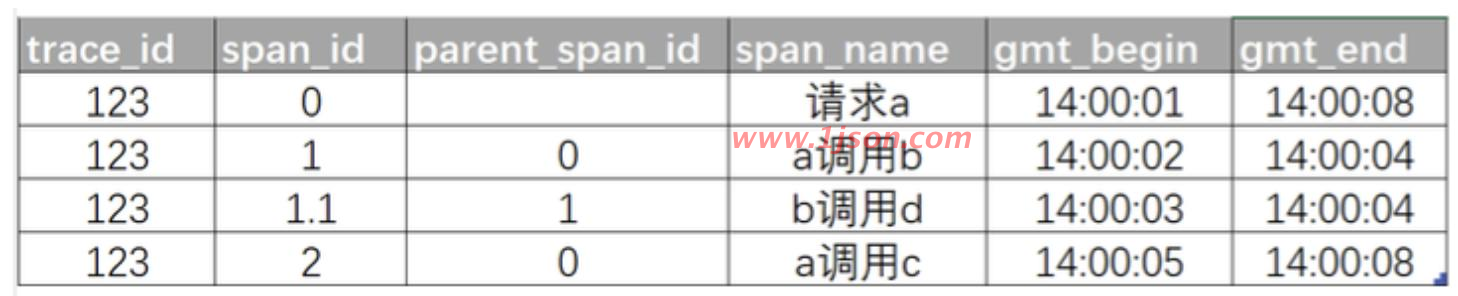
以上实现看起来确实简单,但有以下几个问题需要我们仔细思考一下:
1、怎么自动采集 span 数据
通过探针全局无入侵
2、如何跨进程传递 context
我们知道数据一般分为 header 和 body, 就像 http 有 header 和 body, RocketMQ 也有 MessageHeader,Message Body, body 一般放着业务数据,所以不宜在 body 中传递 context,应该在 header 中传递 context,这样就解决了 context 的传递问题。
3、traceId 如何保证全局唯一
可采用snowflow雪花算法
4、请求量这么多,全部采集会不会影响性能?
如果对每个请求调用都采集,那毫无疑问数据量会非常大,但反过来想一下,是否真的有必要对每个请求都采集呢,其实没有必要,我们可以设置采样频率,只采样部分数据,SkyWalking 默认设置了 3 秒采样 3 次,其余请求不采样。
支持自动和手动探针监控
全自动支持中间件和组件库 https://github.com/apache/incubator-skywalking
手动OpenTracing组件支持列表:https://github.com/opentracing-contrib/meta
自动监控和手动监控可以同时使用,使用手动监控弥补自动监控不支持的组件,甚至私有化组件。
纯 Java 后端分析程序,提供 RESTful 服务,可为其他语言探针提供分析能力。
可借skywalking搜集数据给出分析结果,然后我们就可做自动化运维或devops。
参考
http://www.upyun.com/opentalk/334.html
https://blog.csdn.net/weixin_39866487/article/details/111581322
