
服务热线
135-6963-3175
数据准备、训练及生成准确率丢失率图表
此笔记本(notebook)使用评论文本将影评分为积极(positive)或消极(nagetive)两类。这是一个二元(binary)或者二分类问题,一种重要且应用广泛的机器学习问题。
我们将使用来源于网络电影数据库(Internet Movie Database)的 IMDB 数据集(IMDB dataset),其包含 50,000 条影评文本。从该数据集切割出的25,000条评论用作训练,另外 25,000 条用作测试。训练集与测试集是平衡的(balanced),意味着它们包含相等数量的积极和消极评论。
import tensorflow as tf
from tensorflow import keras
import numpy as np
print(tf.__version__)
imdb = keras.datasets.imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
#让我们花一点时间来了解数据格式。该数据集是经过预处理的:每个样本都是一个表示影评中词汇的整数数组。
#每个标签都是一个值为 0 或 1 的整数值,其中 0 代表消极评论,1 代表积极评论。
print("Training entries: {}, labels: {}".format(len(train_data), len(train_labels)))
#评论文本被转换为整数值,其中每个整数代表词典中的一个单词。首条评论是这样的:
print(train_data[0])
#len(train_data[0]), len(train_data[1])
# 一个映射单词到整数索引的词典
word_index = imdb.get_word_index()
# 保留第一个索引(对所有单词索引的值进行加3操作。这样做是为了将原始的单词索引值(通常从1开始)平移3个位置,以留出0、1、2、3这四个特殊标记的索引位置。)
word_index = {k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"] = 0
word_index["<START>"] = 1
word_index["<UNK>"] = 2 # unknown
word_index["<UNUSED>"] = 3
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
#显示首条评论的文本
print(decode_review(train_data[0]))
#准备数据
#影评——即整数数组必须在输入神经网络之前转换为张量。
#使用 pad_sequences 函数来使长度标准化
#value=word_index["<PAD>"]:value参数指定用于填充的值。在这里,我们使用了特殊标记"<PAD>"的索引值,即word_index["<PAD>"],将该值用于填充。
#padding='post':padding参数指定填充的位置。在这里,我们选择在序列的末尾进行填充,即将填充值添加到每个序列的末尾。
#maxlen=256:maxlen参数指定填充后的序列长度。在这里,我们将所有序列填充/截断为长度为256的序列。
#我们将训练数据中的电影评论序列进行填充操作,使它们的长度一致。这是为了确保输入数据具有相同的维度,以便能够输入到神经网络模型中进行训练。填充后的序列长度为256,不足256的序列将在末尾添加"<PAD>"的索引值进行填充。
train_data = keras.preprocessing.sequence.pad_sequences(train_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
value=word_index["<PAD>"],
padding='post',
maxlen=256)
#构建模型
#(我们定义了一个简单的神经网络模型,用于进行情感分析任务。模型的输入是整数编码的电影评论序列,经过嵌入层和池化层的处理后,
# 最终通过全连接层和输出层得到情感分类的预测结果。模型的总参数数量可以在model.summary()的输出中查看。)
# 输入形状是用于电影评论的词汇数目(10,000 词)(词汇表的大小,即单词的总数。在这里,假设词汇表的大小为10000,即最常见的10000个单词会被考虑在内。)
vocab_size = 10000
#创建一个Sequential模型对象,它是一个线性堆叠模型,可以按顺序添加各个层
model = keras.Sequential()
#Embedding层用于将整数编码的单词索引转换为密集向量表示。在这里,输入的单词索引将被映射到一个16维的向量表示。
model.add(keras.layers.Embedding(vocab_size, 16))
#这个层将输入的每个序列样本的特征进行平均池化,得到一个固定长度的向量表示。
model.add(keras.layers.GlobalAveragePooling1D())
#添加一个具有16个神经元的全连接层。使用ReLU激活函数。
model.add(keras.layers.Dense(16, activation='relu'))
#添加一个具有1个神经元的输出层。使用Sigmoid激活函数,将输出值限制在0到1之间,表示情感分析的二分类结果。
model.add(keras.layers.Dense(1, activation='sigmoid'))
#打印模型的摘要信息,包括每个层的名称、输出形状和参数数量等。
model.summary()
#现在,配置模型来使用优化器和损失函数
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])
#创建一个验证集
x_val = train_data[:10000]
partial_x_train = train_data[10000:]
y_val = train_labels[:10000]
partial_y_train = train_labels[10000:]
#训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=40,
batch_size=512,
validation_data=(x_val, y_val),
verbose=1)
# 保存模型(保存模型结构与权重)
model.save('/Users/PycharmProjects/pythonProject/huigui/model.h5')
#评估模型
results = model.evaluate(test_data, test_labels, verbose=2)
print(results)
#创建一个准确率(accuracy)和损失值(loss)随时间变化的图表
history_dict = history.history
history_dict.keys()
import matplotlib.pyplot as plt
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
#Loss
# “bo”代表 "蓝点"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b代表“蓝色实线”
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
#Accuracy
plt.clf() # 清除数字
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()输出:
2.14.0
Training entries: 25000, labels: 25000
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160000
global_average_pooling1d ( (None, 16) 0
GlobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160289 (626.13 KB)
Trainable params: 160289 (626.13 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Epoch 1/40
30/30 [==============================] - 1s 13ms/step - loss: 0.6918 - accuracy: 0.5704 - val_loss: 0.6898 - val_accuracy: 0.5068
Epoch 2/40
30/30 [==============================] - 0s 9ms/step - loss: 0.6852 - accuracy: 0.6781 - val_loss: 0.6802 - val_accuracy: 0.7350
Epoch 3/40
30/30 [==============================] - 0s 9ms/step - loss: 0.6702 - accuracy: 0.7473 - val_loss: 0.6612 - val_accuracy: 0.7520
Epoch 4/40
30/30 [==============================] - 0s 9ms/step - loss: 0.6439 - accuracy: 0.7714 - val_loss: 0.6316 - val_accuracy: 0.7689
Epoch 5/40
30/30 [==============================] - 0s 9ms/step - loss: 0.6062 - accuracy: 0.7933 - val_loss: 0.5932 - val_accuracy: 0.7872
Epoch 6/40
30/30 [==============================] - 0s 10ms/step - loss: 0.5605 - accuracy: 0.8157 - val_loss: 0.5499 - val_accuracy: 0.8066
Epoch 7/40
30/30 [==============================] - 0s 9ms/step - loss: 0.5112 - accuracy: 0.8350 - val_loss: 0.5049 - val_accuracy: 0.8272
Epoch 8/40
30/30 [==============================] - 0s 9ms/step - loss: 0.4630 - accuracy: 0.8529 - val_loss: 0.4634 - val_accuracy: 0.8360
Epoch 9/40
30/30 [==============================] - 0s 9ms/step - loss: 0.4199 - accuracy: 0.8666 - val_loss: 0.4287 - val_accuracy: 0.8456
Epoch 10/40
30/30 [==============================] - 0s 9ms/step - loss: 0.3829 - accuracy: 0.8751 - val_loss: 0.4001 - val_accuracy: 0.8551
Epoch 11/40
30/30 [==============================] - 0s 9ms/step - loss: 0.3518 - accuracy: 0.8851 - val_loss: 0.3766 - val_accuracy: 0.8599
Epoch 12/40
30/30 [==============================] - 0s 10ms/step - loss: 0.3256 - accuracy: 0.8917 - val_loss: 0.3579 - val_accuracy: 0.8653
Epoch 13/40
30/30 [==============================] - 0s 9ms/step - loss: 0.3036 - accuracy: 0.8976 - val_loss: 0.3433 - val_accuracy: 0.8707
Epoch 14/40
30/30 [==============================] - 0s 9ms/step - loss: 0.2846 - accuracy: 0.9031 - val_loss: 0.3316 - val_accuracy: 0.8736
Epoch 15/40
30/30 [==============================] - 0s 9ms/step - loss: 0.2677 - accuracy: 0.9072 - val_loss: 0.3225 - val_accuracy: 0.8750
Epoch 16/40
30/30 [==============================] - 0s 10ms/step - loss: 0.2532 - accuracy: 0.9133 - val_loss: 0.3141 - val_accuracy: 0.8780
Epoch 17/40
30/30 [==============================] - 0s 11ms/step - loss: 0.2398 - accuracy: 0.9182 - val_loss: 0.3075 - val_accuracy: 0.8793
Epoch 18/40
30/30 [==============================] - 0s 11ms/step - loss: 0.2278 - accuracy: 0.9222 - val_loss: 0.3024 - val_accuracy: 0.8804
Epoch 19/40
30/30 [==============================] - 0s 10ms/step - loss: 0.2168 - accuracy: 0.9259 - val_loss: 0.2976 - val_accuracy: 0.8818
Epoch 20/40
30/30 [==============================] - 0s 9ms/step - loss: 0.2066 - accuracy: 0.9292 - val_loss: 0.2943 - val_accuracy: 0.8815
Epoch 21/40
30/30 [==============================] - 0s 9ms/step - loss: 0.1973 - accuracy: 0.9335 - val_loss: 0.2917 - val_accuracy: 0.8833
Epoch 22/40
30/30 [==============================] - 0s 9ms/step - loss: 0.1881 - accuracy: 0.9383 - val_loss: 0.2891 - val_accuracy: 0.8842
Epoch 23/40
30/30 [==============================] - 0s 9ms/step - loss: 0.1799 - accuracy: 0.9416 - val_loss: 0.2878 - val_accuracy: 0.8842
Epoch 24/40
30/30 [==============================] - 0s 9ms/step - loss: 0.1721 - accuracy: 0.9441 - val_loss: 0.2871 - val_accuracy: 0.8840
Epoch 25/40
30/30 [==============================] - 0s 8ms/step - loss: 0.1650 - accuracy: 0.9475 - val_loss: 0.2859 - val_accuracy: 0.8840
Epoch 26/40
30/30 [==============================] - 0s 8ms/step - loss: 0.1581 - accuracy: 0.9509 - val_loss: 0.2856 - val_accuracy: 0.8853
Epoch 27/40
30/30 [==============================] - 0s 9ms/step - loss: 0.1514 - accuracy: 0.9535 - val_loss: 0.2861 - val_accuracy: 0.8857
Epoch 28/40
30/30 [==============================] - 0s 9ms/step - loss: 0.1455 - accuracy: 0.9558 - val_loss: 0.2875 - val_accuracy: 0.8833
Epoch 29/40
30/30 [==============================] - 0s 10ms/step - loss: 0.1396 - accuracy: 0.9584 - val_loss: 0.2874 - val_accuracy: 0.8854
Epoch 30/40
30/30 [==============================] - 0s 9ms/step - loss: 0.1339 - accuracy: 0.9607 - val_loss: 0.2885 - val_accuracy: 0.8858
Epoch 31/40
30/30 [==============================] - 0s 10ms/step - loss: 0.1291 - accuracy: 0.9618 - val_loss: 0.2919 - val_accuracy: 0.8846
Epoch 32/40
30/30 [==============================] - 0s 9ms/step - loss: 0.1243 - accuracy: 0.9629 - val_loss: 0.2927 - val_accuracy: 0.8838
Epoch 33/40
30/30 [==============================] - 0s 10ms/step - loss: 0.1188 - accuracy: 0.9671 - val_loss: 0.2945 - val_accuracy: 0.8851
Epoch 34/40
30/30 [==============================] - 0s 9ms/step - loss: 0.1139 - accuracy: 0.9680 - val_loss: 0.2959 - val_accuracy: 0.8856
Epoch 35/40
30/30 [==============================] - 0s 9ms/step - loss: 0.1096 - accuracy: 0.9705 - val_loss: 0.3000 - val_accuracy: 0.8836
Epoch 36/40
30/30 [==============================] - 0s 8ms/step - loss: 0.1054 - accuracy: 0.9706 - val_loss: 0.3010 - val_accuracy: 0.8839
Epoch 37/40
30/30 [==============================] - 0s 9ms/step - loss: 0.1011 - accuracy: 0.9728 - val_loss: 0.3041 - val_accuracy: 0.8842
Epoch 38/40
30/30 [==============================] - 0s 8ms/step - loss: 0.0972 - accuracy: 0.9743 - val_loss: 0.3078 - val_accuracy: 0.8812
Epoch 39/40
30/30 [==============================] - 0s 8ms/step - loss: 0.0934 - accuracy: 0.9759 - val_loss: 0.3104 - val_accuracy: 0.8825
Epoch 40/40
30/30 [==============================] - 0s 8ms/step - loss: 0.0898 - accuracy: 0.9769 - val_loss: 0.3138 - val_accuracy: 0.8822
/Users/zhangzhixiang/PycharmProjects/pythonProject/venv/lib/python3.10/site-packages/keras/src/engine/training.py:3079: UserWarning: You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')`.
saving_api.save_model(
782/782 - 1s - loss: 0.3349 - accuracy: 0.8703 - 687ms/epoch - 878us/step
[0.3349497318267822, 0.8703200221061707]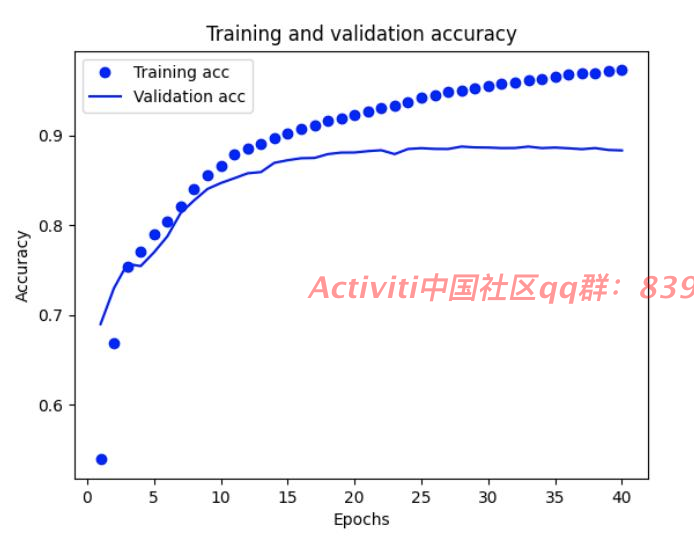
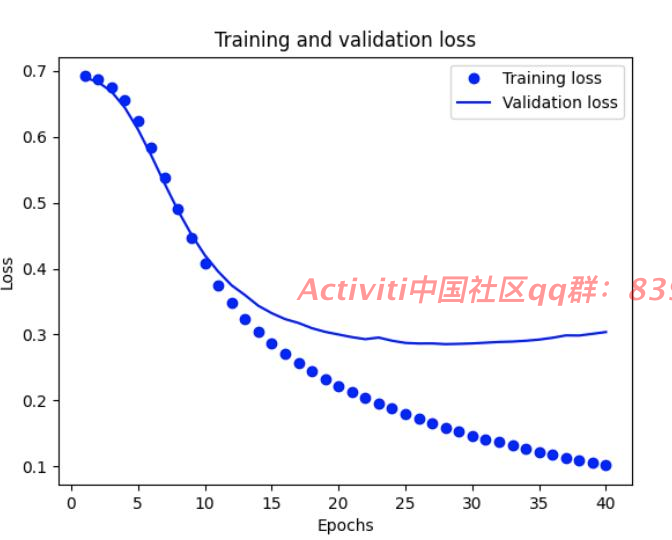
概念:
损失值(loss)和准确率(accuracy)是在机器学习和深度学习中常用的评估指标,用于衡量模型的性能和训练过程的进展。它们在训练和评估模型时起着重要的作用。
1. 损失值(Loss):
- 损失值是衡量模型预测结果与真实值之间差异的度量指标。它表示模型在单个样本或整个数据集上的预测误差大小。
- 在训练过程中,模型的目标是最小化损失值,通过调整模型的参数和权重来使损失值降到最低。
- 常见的损失函数包括均方误差(Mean Squared Error,MSE)、交叉熵(Cross-Entropy)、对数损失(Log Loss)等,具体选择的损失函数取决于问题的性质和模型的输出类型。
2. 准确率(Accuracy):
- 准确率是衡量模型分类任务性能的指标。它表示模型正确分类的样本数与总样本数之间的比例。
- 准确率的取值范围在0到1之间,1表示模型对所有样本都正确分类。
- 准确率在平衡类别分布均匀的数据集上是一个有用的指标,但在类别不平衡的情况下可能会产生误导。
3. 验证损失值(Validation Loss):
- 验证损失值是在模型训练过程中使用验证集计算得出的损失值。它用于评估模型在未见过的数据上的预测性能。
- 验证损失值可以帮助检测模型的过拟合或欠拟合情况。当验证损失值开始增加时,可能表示模型在训练数据上过拟合。
- 通过监控验证损失值的变化,可以选择合适的训练轮次和调整模型的超参数,以获得更好的泛化性能。
4. 验证准确率(Validation Accuracy):
- 验证准确率是在模型训练过程中使用验证集计算得出的准确率指标。它衡量模型在验证集上的分类性能。
- 验证准确率通常与验证损失值一起使用,以提供更全面的模型性能评估。
- 与训练准确率相比,验证准确率更能反映模型在未见过的数据上的分类能力。
损失值和准确率是用于评估和监控模型性能的重要指标。在训练过程中,目标是最小化损失值并提高准确率,以使模型能够更好地进行预测和分类。验证损失值和验证准确率则用于评估模型的泛化能力和选择最佳模型。
该类型模型创建与图像分类模型的区别
输入数据的形状不同:文本模型分类输入是一个整数序列,图像模型分类输入是一个28x28的二维图像。
模型结构不同:文本模型分类使用了Embedding层和GlobalAveragePooling1D层进行文本处理,图像模型使用了Flatten层将图像展平,并添加了全连接层。
