服务热线
135-6963-3175
Sentinel原理
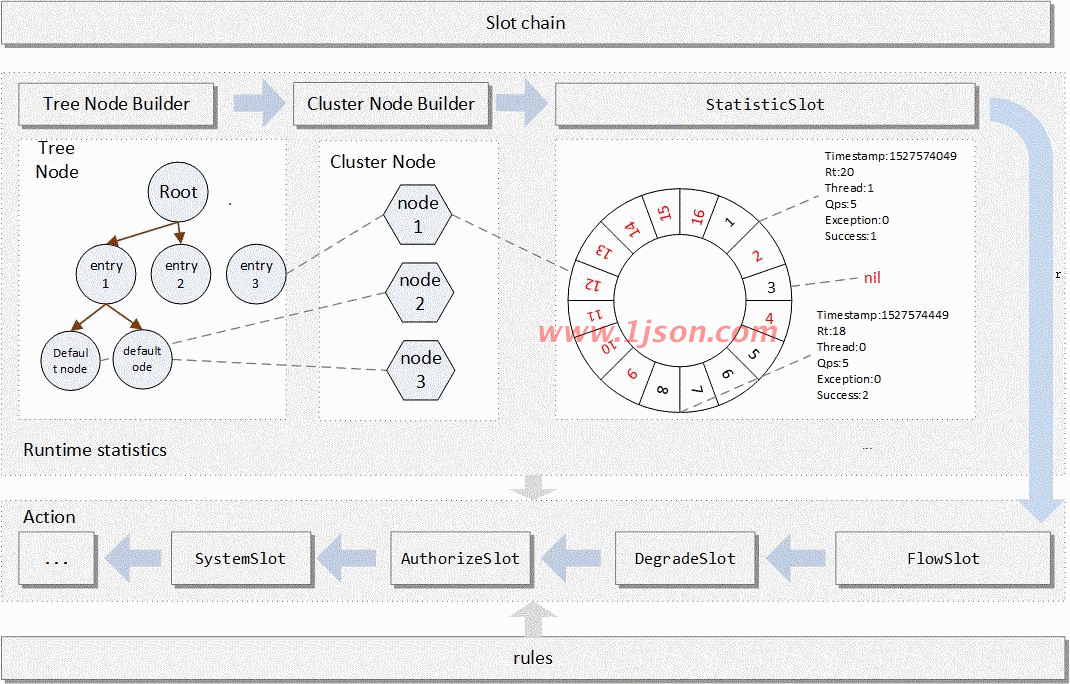
Sentinel 里面,所有的资源都对应一个资源名称(resourceName),每次资源调用都会创建一个 Entry 对象。Entry 可以通过对主流框架的适配自动创建,也可以通过注解的方式或调用 SphU API 显式创建。Entry 创建的时候,同时也会创建一系列功能插槽(slot chain),这些插槽有不同的职责,基于责任链模式。
NodeSelectorSlot 负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;(收集、构建资源树)
ClusterBuilderSlot 则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;(统计)
StatisticSlot 则用于记录、统计不同纬度的 runtime 指标监控信息;(统计)
FlowSlot 则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制;(根据统计进行限流)
DegradeSlot 则通过统计信息以及预设的规则,来做熔断降级;(根据统计及规则熔断降级)
AuthoritySlot 则根据配置的黑白名单和调用来源信息,来做黑白名单控制;(调用源黑白名单控制)
SystemSlot 则通过系统的状态,例如 load1 等,来控制总的入口流量;(根据系统状态控制总入口流量)
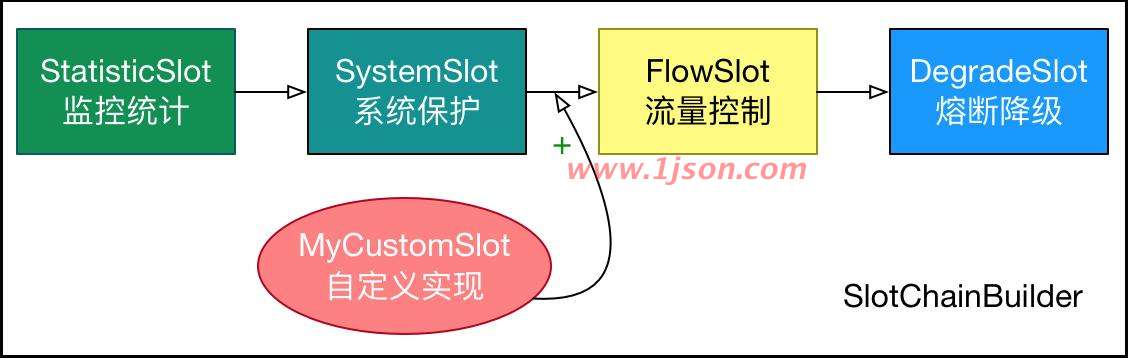
Sentinel 将 ProcessorSlot 作为 SPI 接口进行扩展(1.7.2 版本以前 SlotChainBuilder 作为 SPI),使得 Slot Chain 具备了扩展的能力。您可以自行加入自定义的 slot 并编排 slot 间的顺序,从而可以给 Sentinel 添加自定义的功能。
相关概念:
Resource
任何东西都能被定义成资源,自己提供的服务,调用的服务,甚至一段代码,有了资源才能在资源上定义规则,去进行限流降级之类的操作
在Sentinel中提供了两个默认是Resource分别是StringResourceWrapper和MethodResourceWrapper
Context
Context是上下文的意思,一个线程对应一个Context
其中有三个属性
name:名字
entranceNode:调用链入口
curEntry:当前entry
origin:调用者来源
async:异步
Entry
每次调用 SphU.entry() 都会生成一个Entry入口,该入口中会保存了以下数据:入口的创建时间,当前入口所关联的节点(Node),当前入口所关联的调用源对应的节点。Entry是一个抽象类,他只有一个实现类,在CtSph中的一个静态类:CtEntry
其中有这些属性
createtime
curNode
originNode
error
resourceWrapper
parent
child
chain
context
一个Entry相当于一个token只有正常生成了一个entry才能算pass,不然报异常BlockException肯定是限流了
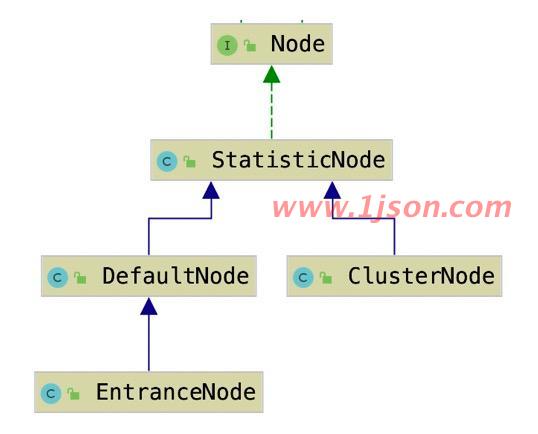
Node节点
节点是用来保存某个资源的各种实时统计信息的,他是一个接口,通过访问节点,就可以获取到对应资源的实时状态,以此为依据进行限流和降级操作。
有几种节点类型
StatisticNode:统计节点
DefaultNode:默认节点,NodeSelectorSlot中创建的就是这个节点
ClusterNode:集群节点
EntranceNode:该节点表示一棵调用链树的入口节点,通过他可以获取调用链树中所有的子节点。
NodeSelectorSlot
收集资源路径,并将这些资源的调用路径以树状结构存储起来,用于根据调用路径进行限流。
ContextUtil.enter("entrance1", "appA");
Entry nodeA = SphU.entry("nodeA");
if (nodeA != null) {
nodeA.exit();
}
ContextUtil.exit();创建了一个名为entrance1的上下文,同时指定调用发起者来源为appA,;接着通过 SphU.entry()请求一个 token,如果该方法顺利执行没有抛 BlockException,表明 token 请求成功。
machine-root / / EntranceNode1 / / DefaultNode(nodeA)
每个 DefaultNode 由资源 ID 和输入名称来标识。换句话说,一个资源 ID 可以有多个不同入口的 DefaultNode。
ContextUtil.enter("entrance1", "appA");
Entry nodeA = SphU.entry("nodeA");
if (nodeA != null) {
nodeA.exit();
}
ContextUtil.exit();
ContextUtil.enter("entrance2", "appA");
nodeA = SphU.entry("nodeA");
if (nodeA != null) {
nodeA.exit();
}
ContextUtil.exit();相同的资源但是Context不同,分别新建 DefaultNode,并以ContextName为key
machine-root / \ / \ EntranceNode1 EntranceNode2 / \ / \ DefaultNode(nodeA) DefaultNode(nodeA)
上面的结构可以通过调用 curl http://localhost:8719/tree?type=root 来显示。
一个资源有可能创建多个DefaultNode(有多个上下文时),那么我们应该如何快速的获取总的统计数据呢?
答案就在下一个Slot(ClusterBuilderSlot)中被解决了。
ClusterBuilderSlot
此插槽用于构建资源的 ClusterNode 以及调用来源节点。ClusterNode 保持某个资源运行统计信息(响应时间、QPS、block 数目、线程数、异常数等)以及调用来源统计信息列表。调用来源的名称由 ContextUtil.enter(contextName,origin) 中的 origin 标记。可通过如下命令查看某个资源不同调用者的访问情况:curl http://localhost:8719/origin?id=caller
具有相同资源名称的共享一个ClusterNode,也就是说,能进入到同一个ClusterBuilderSlot对象的entry方法的请求都是来自同一个资源的,所以这些相同资源需要初始化一个统一的CluserNode用来做流量的汇总统计。
ClusterBuilderSlot原理中,一个ContextName对应的同一个Resource对应ClusterNode为同一个,所以同步新增,或减少记录数,都是基于当前节点和对应的ClusterNode一起统计的。
不管是ClusterNode,或者DefaultNode节点,对其添加,或记录Qps,rt都是基于父类去实现,这样来讲,所有Sentinel最核心的代码就在StatisticNode中。
StatisticSlot
StatisticSlot 是 Sentinel 的核心功能插槽之一,用于统计实时的调用数据。
clusterNode:资源唯一标识的 ClusterNode 的实时统计
origin:根据来自不同调用者的统计信息
defaultnode: 根据入口上下文区分的资源 ID 的 runtime 统计
入口流量的统计
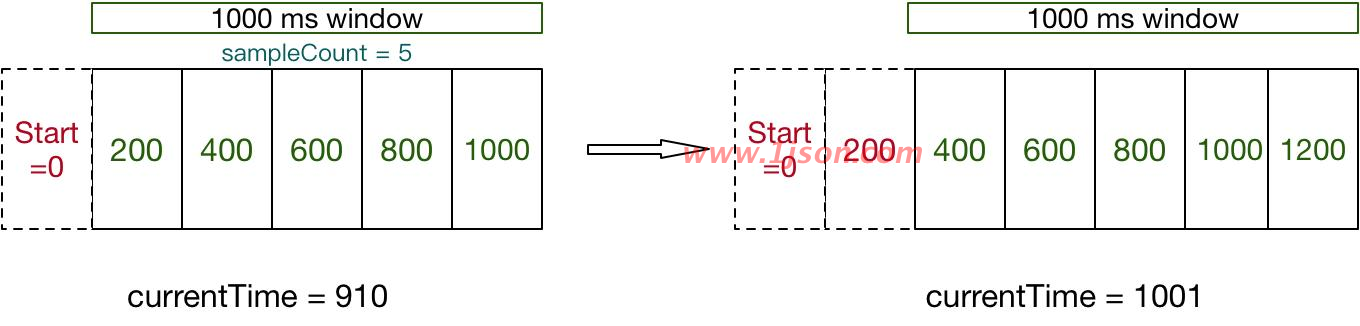
Sentinel 底层采用高性能的滑动窗口数据结构 LeapArray 来统计实时的秒级指标数据,可以很好地支撑写多于读的高并发场景。