服务热线
135-6963-3175
FlowSlot
根据已(NodeSelectorSlot、ClusterNodeBuilderSlot 和 StatisticSlot)收集的运行时统计信息,FlowSlot将使用预先设置的规则来决定是否应阻止传入请求。
代码:
public class FlowRuleChecker {
//根据资源名称获取限流规则列表,并遍历进行条件判断
public void checkFlow(Function<String, Collection<FlowRule>> ruleProvider, ResourceWrapper resource,
Context context, DefaultNode node, int count, boolean prioritized) throws BlockException {
if (ruleProvider == null || resource == null) {
return;
}
Collection<FlowRule> rules = ruleProvider.apply(resource.getName());
if (rules != null) {
for (FlowRule rule : rules) {
if (!canPassCheck(rule, context, node, count, prioritized)) {
throw new FlowException(rule.getLimitApp(), rule);
}
}
}
}
public boolean canPassCheck(/*@NonNull*/ FlowRule rule, Context context, DefaultNode node, int acquireCount,
boolean prioritized) {
String limitApp = rule.getLimitApp();
//如果限流规则没有配置针对来源,则直接默认通过,该值在配置时,默认为default,即对所有调用发起方都生效。
if (limitApp == null) {
return true;
}
//如果是集群限流模式,则调用 passClusterCheck,非集群限流模式则调用 passLocalCheck 方法,
本文重点讲述单节点限流。
//开启了集群模式
if (rule.isClusterMode()) {
return passClusterCheck(rule, context, node, acquireCount, prioritized);
}
//非集群模式
return passLocalCheck(rule, context, node, acquireCount, prioritized);
}
private static boolean passLocalCheck(FlowRule rule, Context context, DefaultNode node, int acquireCount,
boolean prioritized) {
//首先根据流控模式(strategy)选择一个合适的 Node,看到这,大家可以思考一下,这一步骤的目的,
如果为空,则直接返回 true,表示放行。
Node selectedNode = selectNodeByRequesterAndStrategy(rule, context, node);
if (selectedNode == null) {
return true;
}
//执行rule的
//调用 FlowRule 内部持有的流量控制器来判断是否符合流控规则,
最终调用的是 TrafficShapingController canPass 方法。
return rule.getRater().canPass(selectedNode, acquireCount, prioritized);
}
//.......省略代码
}看下selectNodeByRequesterAndStrategy代码:
static Node selectNodeByRequesterAndStrategy(/*@NonNull*/ FlowRule rule, Context context, DefaultNode node) {
// The limit app should not be empty.
String limitApp = rule.getLimitApp();
int strategy = rule.getStrategy();
String origin = context.getOrigin();
//如果限流规则配置的针对的调用方与当前请求实际调用来源匹配(并且不是 default、other)时
if (limitApp.equals(origin) && filterOrigin(origin)) {
//如果流控模式为 RuleConstant.STRATEGY_DIRECT(直接),则从 context 中获取源调用方所代表的 Node
if (strategy == RuleConstant.STRATEGY_DIRECT) {
// Matches limit origin, return origin statistic node.
return context.getOriginNode();
}
return selectReferenceNode(rule, context, node);
//如果流控规则针对的调用方(limitApp) 配置的为 default,表示对所有的调用源都生效,其获取实时统计节点(Node)的处理逻辑为:
} else if (RuleConstant.LIMIT_APP_DEFAULT.equals(limitApp)) {
//如果流控模式为 RuleConstant.STRATEGY_DIRECT,则直接获取本次调用上下文环境对应的节点的ClusterNode
if (strategy == RuleConstant.STRATEGY_DIRECT) {
// Return the cluster node.
return node.getClusterNode();
}
return selectReferenceNode(rule, context, node);
//如果流控规则针对的调用方为(other),此时需要判断是否有针对当前的流控规则,
只要存在,则这条规则对当前资源“失效”(相当于自己调用自己),如果针对该资源没有配置其他额外的流控规则,
则获取实时统计节点(Node)的处理逻辑为
} else if (RuleConstant.LIMIT_APP_OTHER.equals(limitApp)
&& FlowRuleManager.isOtherOrigin(origin, rule.getResource())) {
//如果流控模式为 RuleConstant.STRATEGY_DIRECT(直接),则从 context 中获取源调用方所代表的 Node
if (strategy == RuleConstant.STRATEGY_DIRECT) {
return context.getOriginNode();
}
return selectReferenceNode(rule, context, node);
}
return null;
}从这里可以看出,流控规则针对调用方如果设置为 other,表示针对没有配置流控规则的资源。
代码:
public class DefaultController implements TrafficShapingController {
private static final int DEFAULT_AVG_USED_TOKENS = 0;
private double count;
private int grade;
public DefaultController(double count, int grade) {
this.count = count;
this.grade = grade;
}
@Override
public boolean canPass(Node node, int acquireCount, boolean prioritized) {
//根据grade的类型决定canPass时是累加线程数还是QPS.
int curCount = avgUsedTokens(node);
// 如果已经超过当前时间窗格的通过数上限
curCount-当前已消耗的令牌数量,即当前时间窗口内已创建的线程数量(FLOW_GRADE_THREAD) 或已通过的请求个数
count-流控规则中配置的阔值(即一个时间窗口中总的令牌个数)
if (curCount + acquireCount > count) {
//如果有优先且grade为FLOW_GRADE_QPS
if (prioritized && grade == RuleConstant.FLOW_GRADE_QPS) {
long currentTime;
long waitInMs;
currentTime = TimeUtil.currentTimeMillis();
//尝试借用后续时间窗格的通过数,返回等待时间(尝试抢占下一个滑动窗口的令牌,并返回该时间窗口所剩余的时间,如果获取失败,
则返回 OccupyTimeoutProperty.getOccupyTimeout() 值,该返回值的作用就是当前申请资源的线程将 sleep(阻塞)的时间。)
waitInMs = node.tryOccupyNext(currentTime, acquireCount, count);
//没有达到最大等待时间
//如果 waitInMs 小于抢占的最大超时时间,则在下一个时间窗口中增加对应令牌数,并且线程将sleep
if (waitInMs < OccupyTimeoutProperty.getOccupyTimeout()) {
//等待
//将需要的令牌数添加到borrowArray中未来一个时间窗口
node.addWaitingRequest(currentTime + waitInMs, acquireCount);
//将抢占的未来的令牌数也添加到原来data中的当前时间窗口中
node.addOccupiedPass(acquireCount);
//等待到对用时间窗口到达
sleep(waitInMs);
//这里不是很明白为什么等待 waitMs 之后,还需要抛出 PriorityWaitException,感觉是个bug
// PriorityWaitException indicates that the request will pass after waiting for {@link @waitInMs}.
throw new PriorityWaitException(waitInMs);
}
}
return false;
}
return true;
}
private int avgUsedTokens(Node node) {
if (node == null) {
return DEFAULT_AVG_USED_TOKENS;
}
return grade == RuleConstant.FLOW_GRADE_THREAD ? node.curThreadNum() : (int)(node.passQps());
}
......
}然后看下tryOccupyNext源码:
public class StatisticNode implements Node {
/**
* 尝试抢占未来的令牌,返回值为调用该方法的线程应该 sleep 的时间
* @param currentTime current time millis.当前时间
* @param acquireCount tokens count to acquire.需要申请的token个数
* @param threshold qps threshold.阀值
* @return
* IntervalProperty.INTERVAL 为一个时间间隔,默认1000ms,即1s
*/
@Override
public long tryOccupyNext(long currentTime, int acquireCount, double threshold) {
//即一个时间间隔内产生的最大令牌数,后面的为1,实际上就是1s内定义的阈值令牌数
double maxCount = threshold * IntervalProperty.INTERVAL / 1000;
//获得borrowArray中除去过期的所抢占的未来的令牌数,会调用currentWaiting方法
long currentBorrow = rollingCounterInSecond.waiting();
if (currentBorrow >= maxCount) {
//最大占用超时,以毫秒为单位,500ms
return OccupyTimeoutProperty.getOccupyTimeout();
}
// 1000ms / 2
// 一个时间窗口表示的时间长度
int windowLength = IntervalProperty.INTERVAL / SampleCountProperty.SAMPLE_COUNT;
// currentTime - currentTime % windowLength为该窗口的实际开始时间
// 再加上一个窗口的时间长度减去一个时间间隔
// windowLength 一般为500ms,INTERVAL为1000ms,所以总共要减去500ms
//即实际的开始时间向前退500ms,应该是比他早一个的时间窗口开始时间
long earliestTime = currentTime - currentTime % windowLength + windowLength - IntervalProperty.INTERVAL;
int idx = 0;
/*
* Note: here {@code currentPass} may be less than it really is NOW, because time difference
* since call rollingCounterInSecond.pass(). So in high concurrency, the following code may
* lead more tokens be borrowed.
*/
long currentPass = rollingCounterInSecond.pass();
while (earliestTime < currentTime) {
// 当前窗口所剩余的时间
long waitInMs = idx * windowLength + windowLength - currentTime % windowLength;
//设置的等待时间不能超过一个阈值500ms
if (waitInMs >= OccupyTimeoutProperty.getOccupyTimeout()) {
break;
}
//获取它的之前早的一个窗口的统计的请求数
long windowPass = rollingCounterInSecond.getWindowPass(earliestTime);
if (currentPass + currentBorrow + acquireCount - windowPass <= maxCount) {
return waitInMs;
}
//向后移动一个窗口
earliestTime += windowLength;
//当前一个窗口记录的通过量
currentPass -= windowPass;
idx++;
}
return OccupyTimeoutProperty.getOccupyTimeout();
}
.............
}集群模式
passClusterCheck()
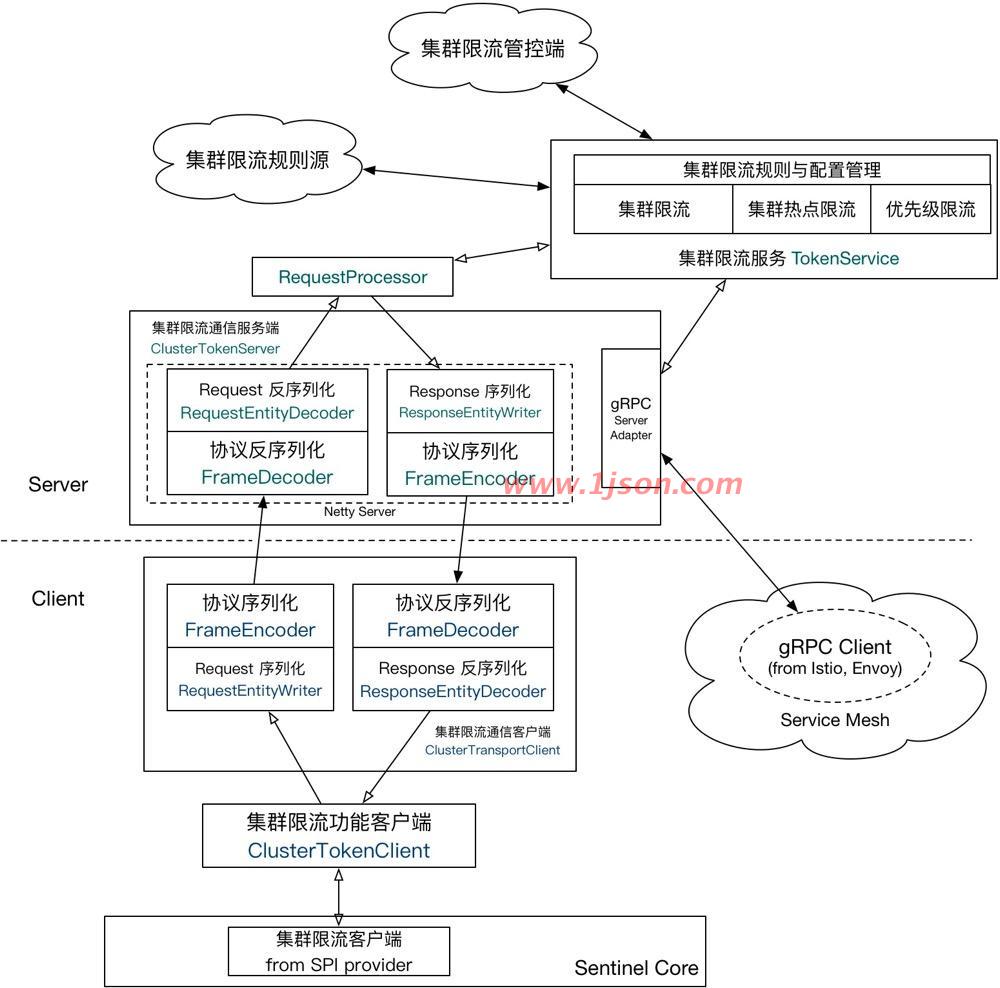
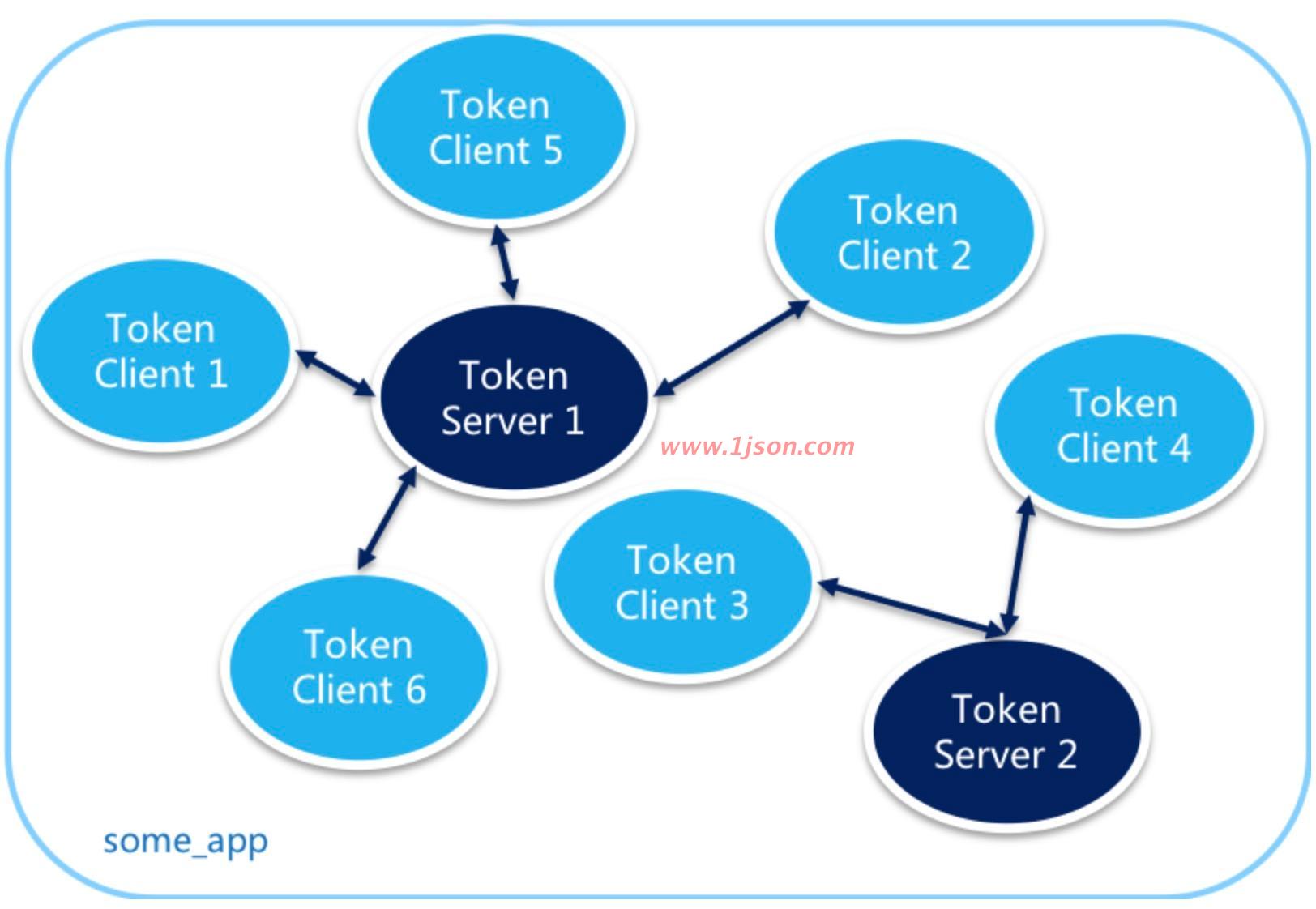
为什么需要集群流控呢?假设需要将某个API的总qps限制在100,机器数可能为50,这时很自然的想到使用一个专门的server来统计总的调用量,其他实例与该server通信来判断是否可以调用,这就是基本的集群流控方式,sentinel的实现就是这样的。
如果服务调用使用轮训或者随机路由方式,理论上可以通过在各个单机上设置流控规则即可(单机qps上限=总qps上限 / 机器数)。集群流控可以解决流量分配不均的问题导致总体流控效果不佳的问题,其可以精确地控制整个集群的调用总量,结合单机限流兜底,可以更好地发挥流量控制的效果,不过由于会与server进行通信,所以性能上会有一定损耗。
集群流控中共有两种身份:
Token Client:集群流控客户端,用于向所属 Token Server 通信请求 token。集群限流服务端会返回给客户端结果,决定是否限流。
Token Server:即集群流控服务端,处理来自 Token Client 的请求,根据配置的集群规则判断是否应该发放 token(是否允许通过)
sentinel-cluster-common-default: 公共模块,包含公共接口和实体
sentinel-cluster-client-default: 默认集群流控 client 模块,使用 Netty 进行通信,提供接口方便序列化协议扩展
sentinel-cluster-server-default: 默认集群流控 server 模块,使用 Netty 进行通信,提供接口方便序列化协议扩展;同时提供扩展接口对接规则判断的具体实现(TokenService),默认实现是复用 sentinel-core 的相关逻辑。
集群规则配置方式
在集群流控的场景下,我们推荐使用动态规则源来动态地管理规则。
对于客户端,我们可以按照原有的方式来向 FlowRuleManager 和 ParamFlowRuleManager 注册动态规则源,例如:
ReadableDataSource<String, List<FlowRule>> flowRuleDataSource = new NacosDataSource<>(remoteAddress, groupId, dataId, parser); FlowRuleManager.register2Property(flowRuleDataSource.getProperty());
对于集群流控 token server,由于集群限流服务端有作用域(namespace)的概念,因此我们需要注册一个自动根据 namespace 生成动态规则源的 PropertySupplier:
// Supplier 类型:接受 namespace,返回生成的动态规则源,类型为 SentinelProperty<List<FlowRule>>
// ClusterFlowRuleManager 针对集群限流规则,ClusterParamFlowRuleManager 针对集群热点规则,配置方式类似
ClusterFlowRuleManager.setPropertySupplier(namespace -> {
return new SomeDataSource(namespace).getProperty();
});然后每当集群限流服务端 namespace set 产生变更时,Sentinel 会自动针对新加入的 namespace 生成动态规则源并进行自动监听,并删除旧的不需要的规则源。
client端处理机制
client端的处理机制和单机是一样的,只不过clusterMode和clusterConfig属性配置上了而已
//flowId 代表全局唯一的规则 ID,Sentinel 集群限流服务端通过此 ID 来区分各个规则,因此务必保持全局唯一。一般 flowId 由统一的管控端进行分配,或写入至 DB 时生成。
//thresholdType 代表集群限流阈值模式。单机均摊模式表示总qps阈值等于机器数*单机qps阈值;全局阈值等于整个集群配置的阈值。
//strategy 集群策略,默认FLOW_CLUSTER_STRATEGY_NORMAL,针对ClusterFlowConfig配置该属性为FLOW_CLUSTER_STRATEGY_NORMAL才合法,除此之外,暂无太多业务意义。
private static boolean passClusterCheck(FlowRule rule, Context context, DefaultNode node, int acquireCount,
boolean prioritized) {
try {
//获取TokenService对象;
TokenService clusterService = pickClusterService();
// 获取不到令牌服务则降级到本地处理
if (clusterService == null) {
return fallbackToLocalOrPass(rule, context, node, acquireCount, prioritized);
}
long flowId = rule.getClusterConfig().getFlowId();
//获取令牌结果
TokenResult result = clusterService.requestToken(flowId, acquireCount, prioritized);
return applyTokenResult(result, rule, context, node, acquireCount, prioritized);
// If client is absent, then fallback to local mode.
} catch (Throwable ex) {
RecordLog.warn("[FlowRuleChecker] Request cluster token unexpected failed", ex);
}
// Fallback to local flow control when token client or server for this rule is not available.
// If fallback is not enabled, then directly pass.
return fallbackToLocalOrPass(rule, context, node, acquireCount, prioritized);
}requestToken负责与token server端通信,入参包括flowId, acquireCount, prioritized,这里是没有Resource信息的,server端通过flowid来获取对应规则进行流控判断。注意,调用writeAndFlush发送请求之后等待响应结果,最大等待时间ClusterClientConfigManager.getRequestTimeout();请求发送过程中,出现任何异常或者返回错误(这里不包括BLOCKED情况),都会默认走降级本地流控逻辑:fallbackToLocalOrPass。
了解了client端处理流程,接下来看下server端处理流程,client和server端都是用netty作为底层网络通信服务:
server端处理机制
Sentinel 集群限流服务端有两种启动方式:
独立模式(Alone),即作为独立的 token server 进程启动,独立部署,隔离性好,但是需要额外的部署操作。独立模式适合作为 Global Rate Limiter 给集群提供流控服务。
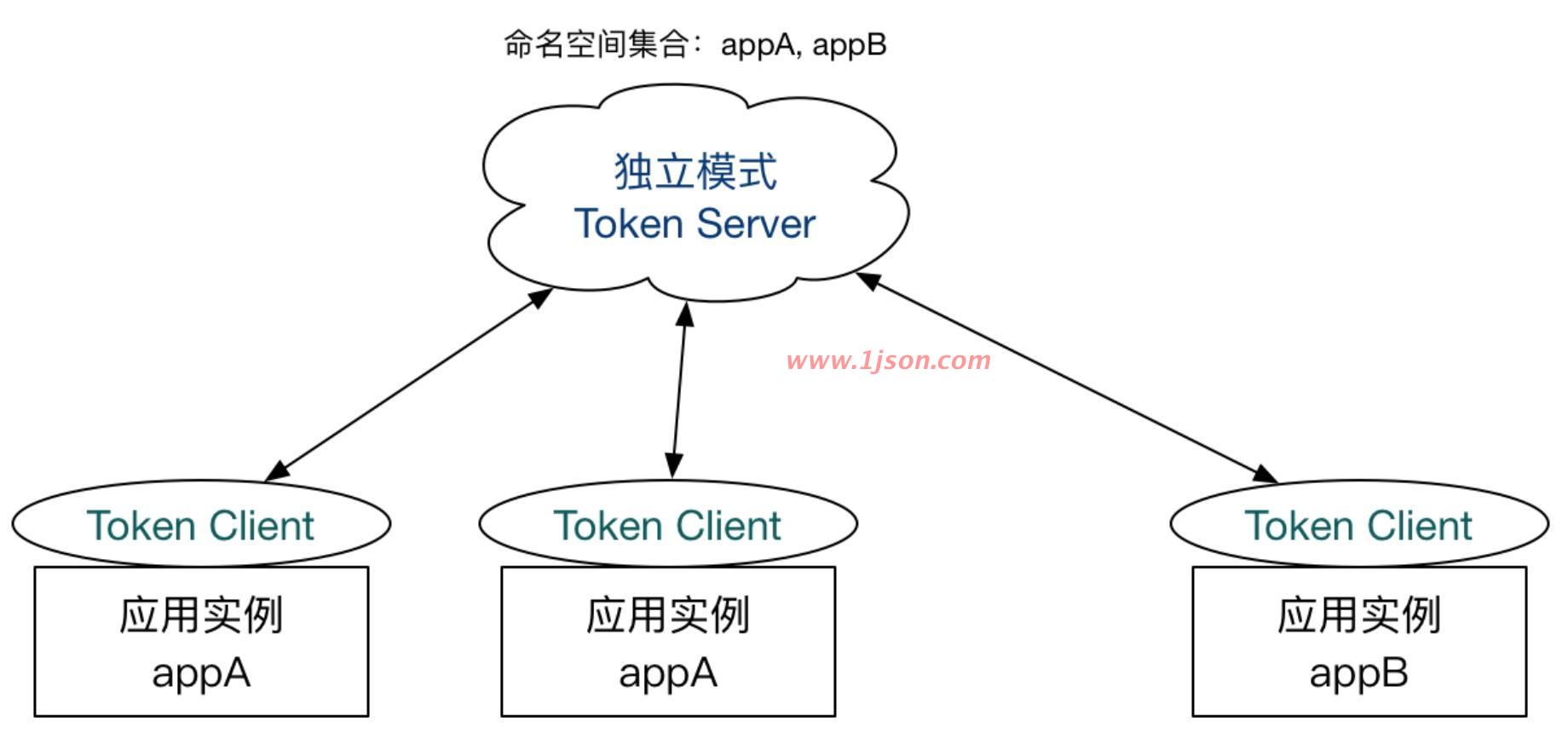
嵌入模式(Embedded),即作为内置的 token server 与服务在同一进程中启动。在此模式下,集群中各个实例都是对等的,token server 和 client 可以随时进行转变,因此无需单独部署,灵活性比较好。但是隔离性不佳,需要限制 token server 的总 QPS,防止影响应用本身。嵌入模式适合某个应用集群内部的流控。
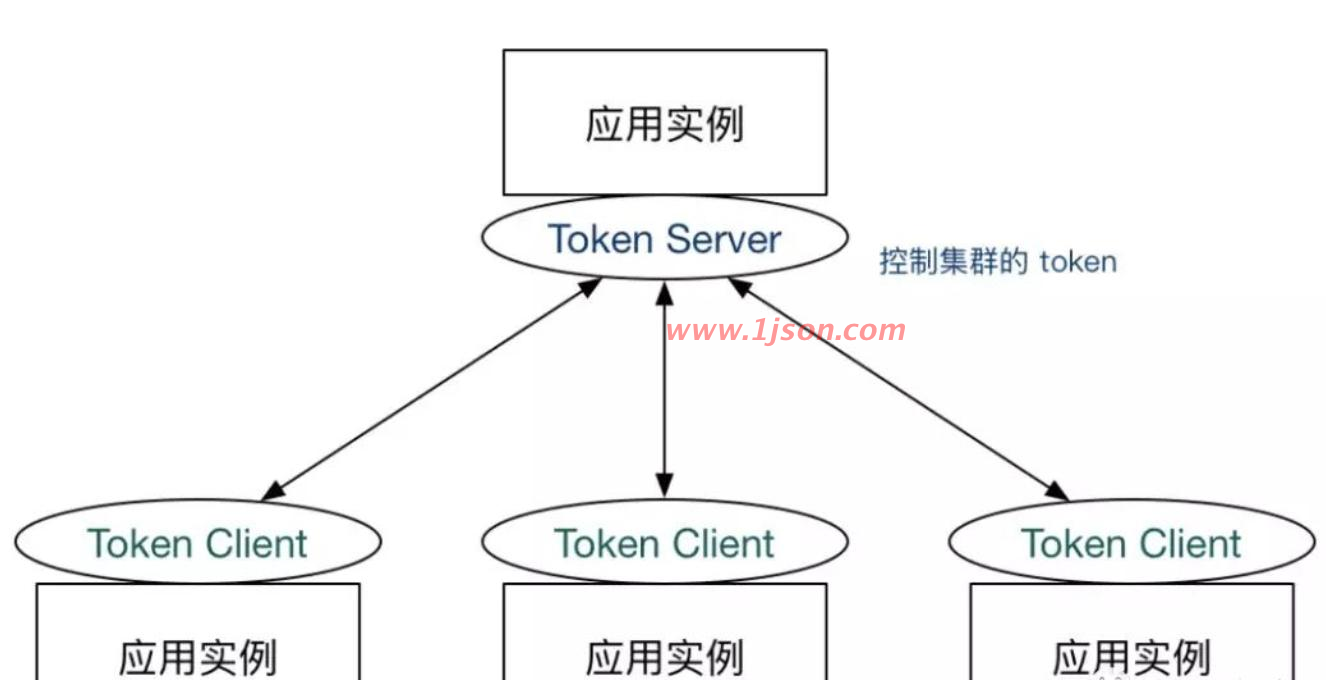
目前针对token server高可用,sentinel并没有对应的解决方案,不过没有并不意味着没考虑,因为默认可以降级走本地流控。sentinel作为一个限流组件,在大部分应用场景中,如果token server挂了降级为本地流控就可以满足了。
如果必须考虑token server高可用,可考虑token server集群部署,每个token server都能访问(或存储)全量规则数据,多个client通过特定路由规则分配到不同的token server(相同类型服务路由到同一个token server,不同类型服务可路由到不同token server),token server故障时提供failover机制即可。如果此时考虑到相同类型服务出现网络分区,也就是一部分服务可以正常与token server通信,另一个部分服务无法正常与token server通信,如果无法正常通信的这部分服务直接进行failover,会导致集群限流不准的问题,可通过zookeeper来保存在线的token server,如果zookeeper中token server列表有变化,再进行failover;此情况下再出现任何形式的网络分区,再执行降级逻辑,执行本地限流。
server端不管是独立模式还是嵌入模式,都是通过NettyTransportServer来启动的:
public void start() {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
p.addLast(new LengthFieldBasedFrameDecoder(1024, 0, 2, 0, 2));
p.addLast(new NettyRequestDecoder());
p.addLast(new LengthFieldPrepender(2));
p.addLast(new NettyResponseEncoder());
p.addLast(new TokenServerHandler(connectionPool));
}
});
b.bind(port).addListener(new GenericFutureListener<ChannelFuture>() {
//
});
}以上逻辑主要是netty启动逻辑,重点关注initChannel方法,这些是往pipeline添加自定义channelHandler,主要是处理粘包、编解码器和业务处理Handler,这里最重要的是TokenServerHandler,因为是请求处理逻辑,所以重点关注其channelRead方法:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
// 全局保存channel
globalConnectionPool.refreshLastReadTime(ctx.channel());
if (msg instanceof ClusterRequest) {
ClusterRequest request = (ClusterRequest)msg;
if (request.getType() == ClusterConstants.MSG_TYPE_PING) {
// ping请求处理,会记录namespace信息
handlePingRequest(ctx, request);
return;
}
// 根据request type获取对应处理器
// 针对集群流控,type为MSG_TYPE_FLOW
RequestProcessor<?, ?> processor = RequestProcessorProvider.getProcessor(request.getType());
ClusterResponse<?> response = processor.processRequest(request);
writeResponse(ctx, response);
}
}针对集群流控,type为MSG_TYPE_FLOW,对应处理器为FlowRequestProcessor。首先会提取请求入参 flowId, acquireCount, prioritized,主要步骤如下:
根据flowId获取规则,为空返回结果NO_RULE_EXISTS;
获取请求namespace对应的RequestLimiter,非空时进行tryPass限流检查,该检查是针对namespace维度;
针对flowId对应规则进行限流检查,acquireCount表示该请求需要获取的token数,数据检查基于滑动时间窗口统计来判断的。
根据限流规则检查之后,会统计相关的PASS/BLOCK/PASS_REQUEST/BLOCK_REQUEST等信息,该流程和单机流控流程是类似的,具体代码不再赘述。处理完成之后,会返回client端处理结果,至此整个集群流控流程就分析完了。
Token Server分配配置
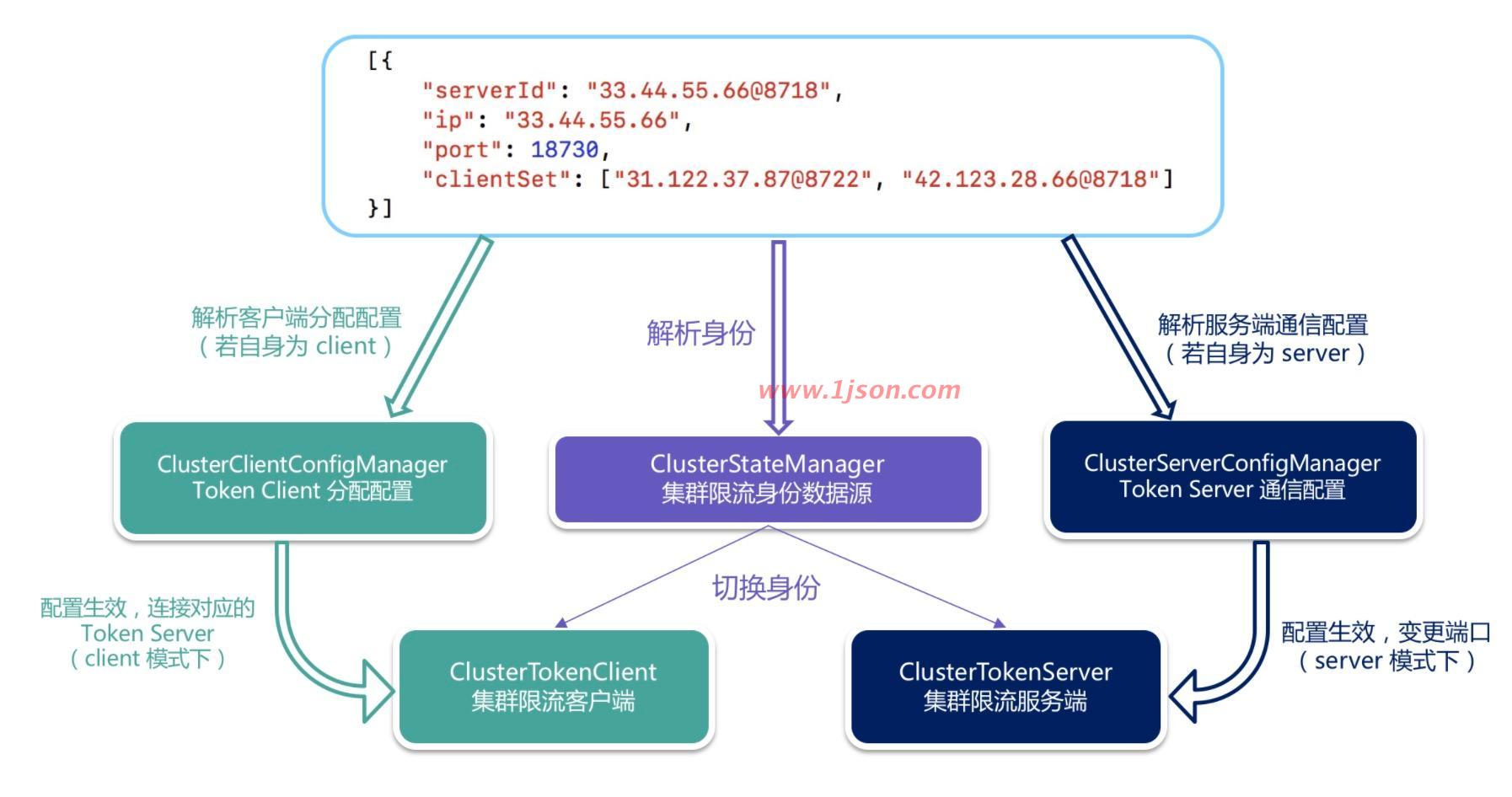
整体扩展架构